kubernetes 重要概念
在实践之前,必须先学习 Kubernetes 的几个重要概念,它们是组成 Kubernetes 集群的基石。
Master
Master 是 Cluster 的大脑,它的主要职责是调度,即决定将应用放在哪里运行。Master 运行 Linux 操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个 Master。
Master节点上运行着以下一组关键进程。
- Kubernetes API Server(kube-apiserver), 提供 HTTP Rest 接口的关键服务程序,kubernets里所有资源增、删、改、查等操作的唯一入口,也是集群控制的入口进程
- Kubernetes Controller Manager(kube-controller-manager),所有资源对象的自动化控制中心(资源对象的大总管)
- Kubernetes Scheduler(kube-scheduler),资源调度(pod)的进程(调度室)
- etcd Server,Kubernetes 里所有资源对象的数据全部是保持在etcd中
Node
Node 的职责是运行容器应用。Node 由 Master 管理,Node 负责监控并汇报容器的状态,并根据 Master 的要求管理容器的生命周期。Node 运行在 Linux 操作系统,可以是物理机或者是虚拟机。
Node运行着一些关键进程:
- kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master节点密切协作,实现集群管理的基本功能。
- kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件。
- Docker Engine (docker):Docker引擎,负责本机的容器创建和管理工作。
Pod
Pod 是 Kubernetes 的最小工作单元。每个 Pod 包含一个或多个容器。Pod 中的容器会作为一个整体被 Master 调度到一个 Node 上运行。(注意:可以把pod想象成豌豆荚,豌豆就是容器,可以有一个或多个。)
说到Pod,简单介绍其概念。首先,Pod运行在一个我们称之为节点(Node)的环境中,这个节点可能是物理机或虚拟机,通常一个节点上上面运行几百个Pod;其次每个Pod运行着一个特殊的被称之为根容器(Pause),和一组用户容器组成,这些业务容器共享根容器(Pause)的网络栈和Volume挂载卷,因此它们之间的通信和数据交换效率更为高效。在设计时我们可以充分利用这一特性将一组密切相关的服务进程放到同一个Pod中。最后需要注意的是并不是每一个Pod和它里面运行的容器都能映射到一个Service上,只有那些提供服务的一组Pod才会被映射成一个服务。
静态Pod & 普通Pod
普通的Pod:
普通Pod一旦被创建,就会被放入到etcd中存储,随后会被Kubernetes Master调度到某个具体的Node上并进行绑定(Binding),随后该Pod 被对应的Node上的kubelet进程实例化成一组相关的docker容器运行起来。
当Pod里的某个容器停止时,Kubernetes会自动检测到这个问题并且重新启动这个Pod (重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上所有的Pod从新调度到其他节点上。静态Pod (STatic Pod):
静态Pod不存放在Kubernetes的etcd存储里,而是存放在某个具体的Node上的文件中,并且只在此Node上启动运行。
静态Pod是由kubelet进行管理的仅存在于特定Node上的Pod。他们不能通过API Server进行管理,无法与ReplicationController(RC)、Deployment、或者DaemonSet进行关联,并且kubelet也无法对它们进行健康检查。静态Pod总是由kubelet进行创建的,并且总是在kubelet所在的Node上运行的
副本控制器类型(Pod叫副本)
- ReplicationController (简称为RC)
- ReplicaSet (简称为RS)
- Deployment
- StatefulSet
- DaemonSet
- Job,Cronjob
Kubernetes 引入 Pod 主要基于下面两个目的:
可管理性:
有些容器天生就是需要紧密联系,一起工作。Pod 提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes 以 Pod 为最小单位进行调度、扩展、共享资源、管理生命周期。通信和资源共享:
Pod 中的所有容器使用同一个网络 namespace,即相同的 IP 地址和 Port 空间。它们可以直接用 localhost 通信。同样的,这些容器可以共享存储,当 Kubernetes 挂载 volume 到 Pod,本质上是将 volume 挂载到 Pod 中的每一个容器。
Pods 有两种使用方式:
运行单一容器:
one-container-per-Pod 是 Kubernetes 最常见的模型,这种情况下,只是将单个容器简单封装成 Pod。即便是只有一个容器,Kubernetes 管理的也是 Pod 而不是直接管理容器。运行多个容器:
但问题在于:哪些容器应该放到一个 Pod 中?
答案是:这些容器联系必须 非常紧密,而且需要 直接共享资源。
举个例子:
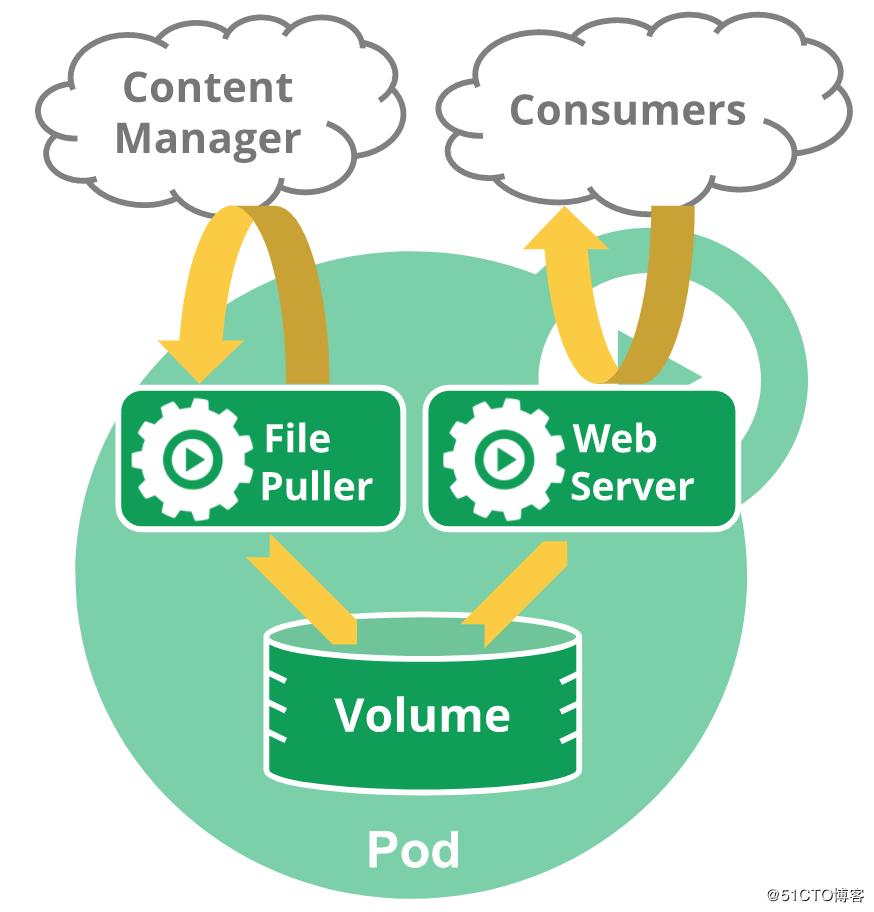
下面这个 Pod 包含两个容器:一个 File Puller,一个是 Web Server。他们两个container的net namespace、uts namespace、ipc namespace是属于共享的。 mnt namespace、user namespace、pid namespace是互相隔离的。
Label:
Label是Kubernetes系统中另外一个核心概念。一个Label是一个key=value的键值对,其中key与vaue由用户自己指定。Label可以附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去,Label通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。
我们可以通过指定的资源对象捆绑一个或多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便地进行资源分配、调度、配置、部署等管理工作。例如:部署不同版本的应用到不同的环境中;或者监控和分析应用(日志记录、监控、告警)等。一些常用等label示例如下。
1 | |
Label相当于我们熟悉的“标签”,給某个资源对象定义一个Label,就相当于給它打了一个标签,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象,Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制。
Label Selector可以被类比为SQL语句中的where查询条件,例如,name=redis-slave这个label Selector作用于Pod时,可以被类比为select * from pod where pod’s name = ‘redis-slave’这样的语句。当前有两种Label Selector的表达式:基于等式的(Equality-based)和基于集合的(Set-based),前者采用“等式类”的表达式匹配标签,下面是一些具体的例子。
基于等式的表达式匹配标签实例:
name=redis-slave:匹配所有具有标签name=redis-slave的资源对象。
env != production:匹配所有不具有标签env=production的资源对象。基于集合方式的表达式匹配标签实例:
name in (redis-master,redis-slave):匹配所有具有标签name=redis-master或者name=redis-slave的资源对象。
name notin (php-frontend):匹配所有不具有标签name=php-frontend的资源对象。
可以通过多个Label Selector表达式的组合实现复杂的条件,多个表达式之间用“,”进行分隔即可,几个条件之间是“AND”的关系,即同时满足多个条件,比如下面的例子:
1 | |
Label Selector在Kubernetes中多重要使用场景有以下几处:
- kube-controller进程通过资源对象RC上定义都Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量始终符合预期设定的全自动控制流程。
- kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载均衡机制。
- 通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略,kube-scheduler进程可以实现Pod“定向调度”的特性。
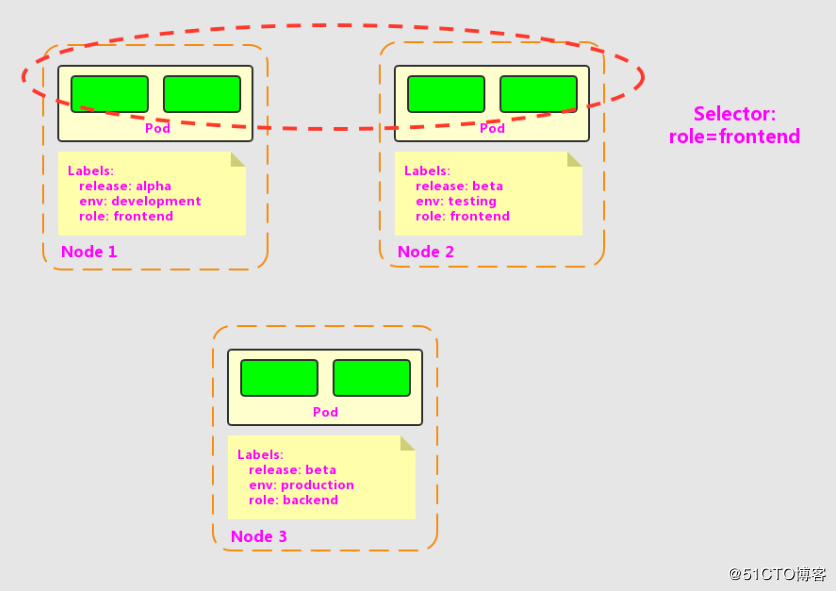
前面我们只是介绍了一个name=XXX的Label Selector。让我们看一个更复杂的例子。假设为Pod定义了Label: release、env和role,不同的Pod定义了不同的Label值,如图1.7所示,如果我们设置了“role=frontend”的Label Selector,则会选取到Node 1和Node 2上到Pod。
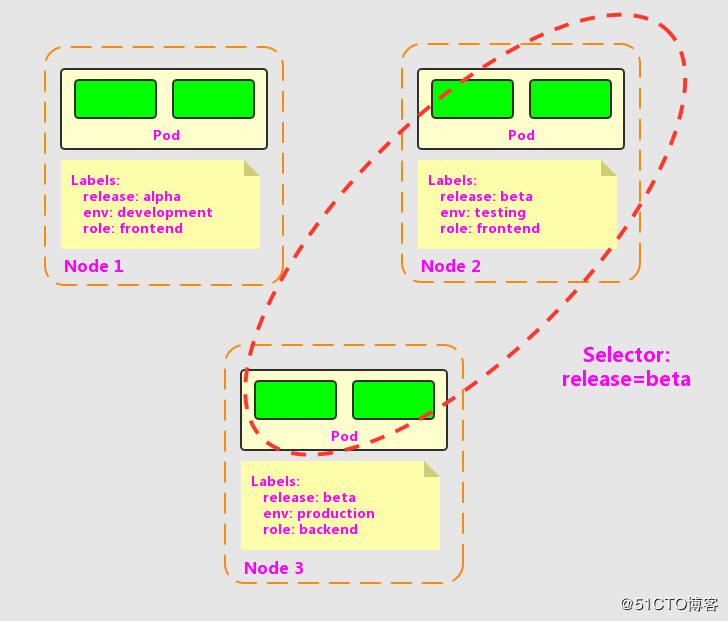
而设置“release=beta”的Label Selector,则会选取到Node 2和Node 3上的Pod,如下图所示。
总结:使用Label可以給对象创建多组标签,Label和Label Selector共同构成了Kubernetes系统中最核心的应用模型,使得被管理对象能够被精细地分组管理,同时实现了整个集群的高可用性。
Service和ReplicationController
对于这两种对象的Label选择器是用map定义在json或者yaml文件中的,并且只支持基于等式(Equality-based)的条件:
1 | |
要么:
1 | |
此选择器(分别为json或yaml格式)等同于component=redis或component in (redis)。
支持set-based的资源
Job,Deployment,Replica Set,和Daemon Set,支持基于集合方式(set-based)的两种表达式。
1 | |
matchLabels 是一个{key,value}的映射。一个单独的 {key,value} 。
1 | |
注释:以上实例表示
key键tieroperator操作符invalues值[cache,backup]
表示key键tier要包含cache和backup
matchExpressions 是一个pod的选择器条件的list 。有效运算符包含In, NotIn, Exists, 和DoesNotExist。在In和NotIn的情况下,value必须不能为空列表。Exists和DoesNotExist的情况下,value必须为空列表。当包含 matchLabels 和 matchExpressions都纯在时,会用AND符号连接,他们必须都被满足才能完成匹配。