Kubernetes之Service
概述:
Service是Kubernetes中最核心的概念,正是因为对此概念的支持,Kubernetes在某种角度下可以被看成是一种微服务平台。Kubernetes中的pod并不稳定,比如由ReplicaSet、Deployment、DaemonSet等副本控制器创建的pod,其副本数量、pod名称、pod所运行的节点、pod的IP地址等,会随着集群规模、节点状态、用户缩放等因素动态变化。Service是一组逻辑pod的抽象,为一组pod提供统一入口,用户只需与service打交道,service提供DNS解析名称,负责追踪pod动态变化并更新转发表,通过负载均衡算法最终将流量转发到后端的pod。
Service的实现模型:
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName 的形式。 在 Kubernetes v1.0 版本,代理完全在 userspace。在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。 从 Kubernetes v1.2 起,默认就是 iptables 代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。在 Kubernetes v1.0 版本,Service 是 “4层”(TCP/UDP over IP)概念。 在 Kubernetes v1.1 版本,新增了 Ingress API(beta 版),用来表示 “7层”(HTTP)服务。
kube-proxy 这个组件始终监视着apiserver中有关service的变动信息,获取任何一个与service资源相关的变动状态,通过watch监视,一旦有service资源相关的变动和创建,kube-proxy都要转换为当前节点上的能够实现资源调度规则(例如:iptables、ipvs)
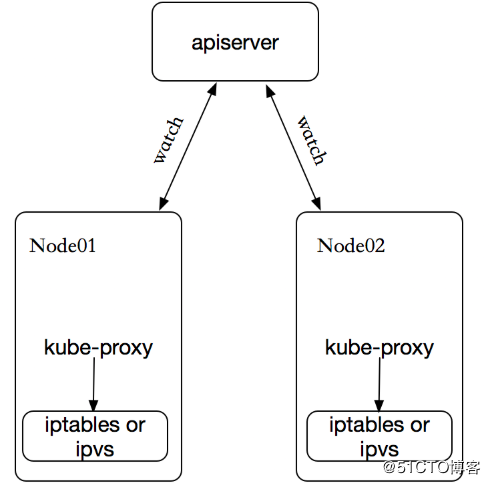
如果某个服务后端pod发生变化,标签选择器适应的pod有多一个,适应的信息会立即反映到apiserver上,而kube-proxy一定可以watch到etc中的信息变化,而将它立即转为ipvs或者iptables中的规则,这一切都是动态和实时的,删除一个pod也是同样的原理。如图:
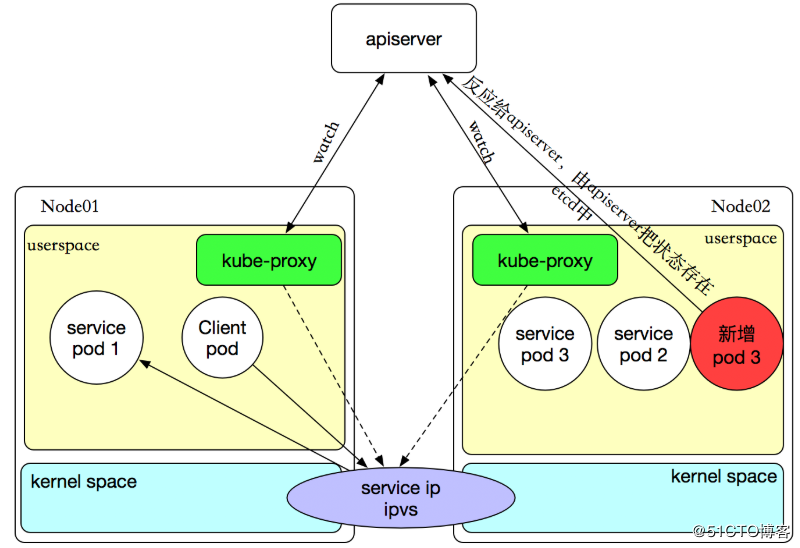
原理:
本节定义一个service示例并说明其工作原理。假设已经通过Deployment副本控制器创建了3个pod,每个pod包含”app=Myapp”标签,每个pod暴露端口9376。之所以假设已经有3个pod实例是为了方便说明service工作原理,推荐的做法是先创建service后创建pod。以下是service声明:(service是靠标签选择器来识别是不是同一个service,service不是一个应用程序也不是一个组件,只是在iptables创建了一个DNAT转发规则而已。)
1 | |
工作过程如下 (Endpoint=Pod IP+ContainerPort):
- 为实例分配置集群虚拟IP。如果在声明时明确指定集群虚拟IP,则分配指定IP,如未指定则自动分配。
- 根据实例名称、分配的集群虚拟IP、端口号创建DNS条目。
- 根据标签选择器聚合符合条件的节点,并创建相应endpoint,endpoint包含所有符合条件pod的ip地址与端口号。
- kube-proxy运行在集群中每一个节点上,并持续监控集群中service、endpoint变更,根据监控结果设置转发规则,将一个集群虚拟IP、端口与一个或者多个pod的IP、端口映射起来。
- 当在集群内部通过服务名称访问创建的service时,首先由DNS将服务名称转换成集群虚拟IP与端口号,kube-proxy根据转发规则对service的流量计算负载均衡、转发到位于后端的pod。
无标签选择器service
当与service对应的后端位于集群外部时,因为集群中没有相关的pod实例,因此这种情况下就不需要标签选择器。有标签选择器时系统自动查询pod并创建相应的endpoint,无标签选择器时需要用户手动创建endpoint。
如下情况下可以使用:
- 希望在生产环境中使用外部的数据库集群,但测试环境使用自己的数据库。
- 希望服务指向另一个 Namespace 中或其它集群中的服务。
- 正在将工作负载转移到 Kubernetes 集群,和运行在 Kubernetes 集群之外的 backend。
1 | |
由于这个 Service 没有标签选择器,就不会创建相关的 Endpoints 对象。可以手动将 Service 映射到指定的 Endpoints:
1 | |
注意:Endpoint IP 地址不能是 loopback(127.0.0.0/8)、 link-local(169.254.0.0/16)、或者 link-local 多播(224.0.0.0/24)。
注意:除需要手动创建endpoint外,无标签选择器与有标签选择器的servcie工作过程完全相同。请求将被路由到用户定义的 Endpoint(该示例中为 1.2.3.4:9376)
kube-proxy有以下三种工作模式:
- userspace 代理模式:
- iptables 代理模式:
- ipvs 代理模式:
ipvs vs. iptables
我们知道kube-proxy支持 iptables 和 ipvs 两种模式, 在kubernetes v1.8 中引入了 ipvs 模式,在 v1.9 中处于 beta 阶段,在 v1.11 中已经正式可用了。iptables 模式在 v1.1 中就添加支持了,从 v1.2 版本开始 iptables 就是 kube-proxy 默认的操作模式,ipvs 和 iptables 都是基于netfilter的,那么 ipvs 模式和 iptables 模式之间有哪些差异呢?
- 1、ipvs 为大型集群提供了更好的可扩展性和性能
- 2、ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
- 3、ipvs 支持服务器健康检查和连接重试等功能
ipvs 依赖 iptables
ipvs 会使用 iptables 进行包过滤、SNAT、masquared(伪装)。具体来说,ipvs 将使用ipset来存储需要DROP或masquared的流量的源或目标地址,以确保 iptables 规则的数量是恒定的,这样我们就不需要关心我们有多少服务了
既然每个Pod都会被分配一个单独的IP地址,而且每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,现在多个Pod副本组成了一个集群来提供服务,那么客户端如何来访问它们呢?一般的做法是部署一个负载均衡器(软件或硬件),为这组Pod开启一个对外的服务端口如9376端口,并且将这些Pod的Endpoint列表加入9376端口的转发列表中,客户端就可以通过负载均衡器的对外IP地址+服务端口来访问服务,而客户端的请求最后会被转发到哪个Pod,则由负载均衡器的算法所决定。
Kubernetes也遵循了上述常规做法,运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话机制。但Kubernetes发明了一种很巧妙又影响深远的设计:Service不是共用一个负载均衡的IP地址,而是每个Service分配了全局唯一的虚拟IP地址,这个虚拟IP地址被称为Cluster IP。这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。
我们知道,Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。而Service一旦被创建,Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内。它的Cluster IP不会发生改变。于是,服务发现这个棘手的问题在Kubernetes的架构里也得到轻松解决:只要用Service的Name与Service的Cluster IP地址做一个DNS域名映射即可完美解决问题。现在想想,这真是一个很棒的设计。
定义 Service
说了这么久,下面我们动手创建一个Service,来加深对它的理解。首先我们创建一个名为tomcat-service.yaml的定义文件,内容如下:
1 | |
上述内容定义了一个名为“tomcat-service”的Service,它的服务端口为8080,拥有“tier-frontend”这个Label的所有Pod实例都属于它,运行下面的命令进行创建:
1 | |
运行下面的命令可以查看tomcat-service的Endpoint列表,其中172.17.1.3是Pod的IP地址,端口8080是Container暴露的端口:
1 | |
你可能有疑问:“说好的Service的Cluster IP呢?怎么没有看到?”我们运行下面的命令即可看到tomcat-service被分配的Cluster IP及更多的信息:
1 | |
1 | |
在spec.ports的定义中,targetPort属性用来确定提供该服务的容器所暴露(EXPOSE)的端口号,即具体业务进程在容器内的targetPort上提供TCP/IP接入;而port属性则定义了Service的虚拟端口。如果没有指定targetPort,则默认targetPort与port相同。
选择自己的 IP 地址
在 Service 创建的请求中,可以通过设置 spec.clusterIP 字段来指定自己的集群 IP 地址。比如,希望替换一个已经已存在的 DNS 条目,或者遗留系统已经配置了一个固定的 IP 且很难重新配置。用户选择的 IP 地址必须合法,并且这个 IP 地址在 service-cluster-ip-range CIDR 范围内,这对 API Server 来说是通过一个标识来指定的。如果 IP 地址不合法,API Server 会返回 HTTP 状态码 422,表示值不合法。
Service多端口问题。
很多服务都存在多个端口的问题,通常一个端口提供业务服务,另外一个端口提供管理服务,比如Mycat、Codis等常见中间件。Kubernetes Service支持多个Endpoint,在存在多个Endpoint的情况下,要求每个Endpoint定义一个名字区分。下面是Tomcat多端口的Service定义样例:
1 | |
多端口为什么需要給每个端口命名呢?这就涉及Kubernetes的服务发现机制了,我们接下来进行讲解。
Kubernetes的服务发现机制
kubernetes 提供了 service 的概念可以通过 VIP 访问 pod 提供的服务,但是在使用的时候还有一个问题:怎么知道某个应用的 VIP?比如我们有两个应用,一个 app,一个 是 db,每个应用使用RC(控制器)进行管理,并通过 service 暴露出端口提供服务。app 需要连接到 db 应用,我们只知道 db 应用的名称,但是并不知道它的 VIP 地址。
环境变量方式
最早时Kubernetes采用了Linux环境变量的方式解决这个问题,即每个Service生成一些对应的Linux环境变量(ENV),并在每个Pod的容器在启动时,自动注入这些环境变量。
不同服务的环境变量用名称区分,例如:
{SVCNAME}_SERVICE_HOST and {SVCNAME}_SERVICE_PORT
如果服务有多个端口则端口的环境变量名称为 {SVCNAME}SERVICE{PORTNAME}_PORT。
以下是tomcat-service产生的环境变量条目:
1 | |
DNS方式:
一个可选(尽管强烈推荐)集群插件 是 DNS 服务器。 DNS 服务器监视着创建新 Service 的 Kubernetes API,从而为每一个 Service 创建一组 DNS 记录。 如果整个集群的 DNS 一直被启用,那么所有的 Pod 应该能够自动对 Service 进行名称解析。
例如,有一个名称为 “my-service” 的 Service,它在 Kubernetes 集群中名为 “my-ns” 的 Namespace 中,为 “my-service.my-ns” 创建了一条 DNS 记录。 在名称为 “my-ns” 的 Namespace 中的 Pod 应该能够简单地通过名称查询找到 “my-service”。 在另一个 Namespace 中的 Pod 必须限定名称为 “my-service.my-ns”。 这些名称查询的结果是 Cluster IP。
Kubernetes 也支持对端口名称的 DNS SRV(Service)记录。 如果名称为 “my-service.my-ns” 的 Service 有一个名为 “http” 的 TCP 端口,可以对 “_http._tcp.my-service.my-ns” 执行 DNS SRV 查询,得到 “http” 的端口号。
Kubernetes DNS 服务器是唯一的一种能够访问 ExternalName 类型的 Service 的方式。 更多信息可以查看DNS Pod 和 Service。
Headless Service(无头服务):
在定义service时,如果.spec.clusterIP被指定为固定值则为服务分配指定的IP,如果.spec.clusterIP字段没有出现在配置中,则自动分配集群虚拟IP。但如果.spect.clusterIP的值被指定为”None”,此时创建的服务就被称为无头服务,其行为与普通服务有很大区别。首先不为服务分配集群虚拟IP,自然也就不能在DNS插件中添加服务相关条目。运行在各节点上的kube-proxy不为其添加转发规则,自然也就无法利用kube-proxy的转发、负载均衡功能。
虽然不向DNS插件添加服务相关条目,但可能添加其它条目,DNS 如何实现自动配置,依赖于 Service 是否定义了 selector。
配置 Selector:
此种情况下,系统仍然根据标签选择器创建endpoint,并根据endpoint向DNS插件中添加条目。比如命名空间为”my-ns”,服务名称为”my-headless”,endpoing指向的pod名称为pod1、pod2,则向DNS插件中添加的条目类似于”pod1.my-headless.my-ns”与”pod1.my-headless.my-ns”,此时DNS中的条目直接指向pod。在StatefulSet类型资源中,使用无头服务为其中的pod提供名称解析服务,只所以可行,其实是因为StatefulSet能保证其管理的pod有序,名称地址等特征保持不变。
1 | |
不配置 Selector:
对没有定义 selector 的 Headless Service,Endpoint 控制器不会创建 Endpoints 记录。 然而 DNS 系统会查找并配置,无论是:
- ExternalName 类型 Service 的 CNAME 记录
- 记录:与 Service 共享一个名称的任何 Endpoints,以及所有其它类型
DNS解析正常 Service如下:
1 | |
1 | |
DNS解析Headless Service如下:
1 | |
1 | |
外部系统访问Service的问题
本文以上示例都以默认服务类型为前提,实际上kubernetes暴露服务IP的类型有四种,service.spec.type允许指定一个需要的类型,默认是 ClusterIP 类型。Type 的取值以及行为如下:
- ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的 ServiceType。
- NodePort:通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求
: ,可以从集群的外部访问一个 NodePort 服务。 - LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。
首先,Node IP是Kubernetes集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个Kubernetes集群。这也表明了Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务时,必须要通过Node IP进行通信。
其次,Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,前面我们说过,Kubernetes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。
最后,我们说说Service的Cluster IP,它也是一个虚拟的IP,但更像是一个“伪造”的IP网络,原因有以下几点。
- Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)。
- Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础,并且它们属于Kubernetes集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作。
- 在Kubernetes集群之内,Node IP网、Pod IP网与Clsuter IP之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP路由有很大的不同。
根据上面的分析和总结,我们基本明白了:Service的Cluster IP属于Kubernetes集群内部的地址,无法在集群外部直接使用这个地址。那么矛盾来了:实际上我们开发的业务系统中肯定多少由一部分服务是要提供給Kubernetes集群外部的应用或者用户来使用的,典型的例子就是Web端的服务模块,比如上面的tomcat-service,那么用户怎么访问它?
采用NodePort是解决上述问题的最直接、最常用的做法。具体做法如下,以tomcat-service为例,我们在Service的定义里做如下扩展即可(黑体字部分):
1 | |
其中,nodePort:31002这个属性表明我们手动指定tomcat-service的NodePort为31002,否则Kubernetes会自动分配一个可用的端口。接下来,我们在浏览器里访问http://
:31002,就可以看到Tomcat的欢迎界面了,如图所示。
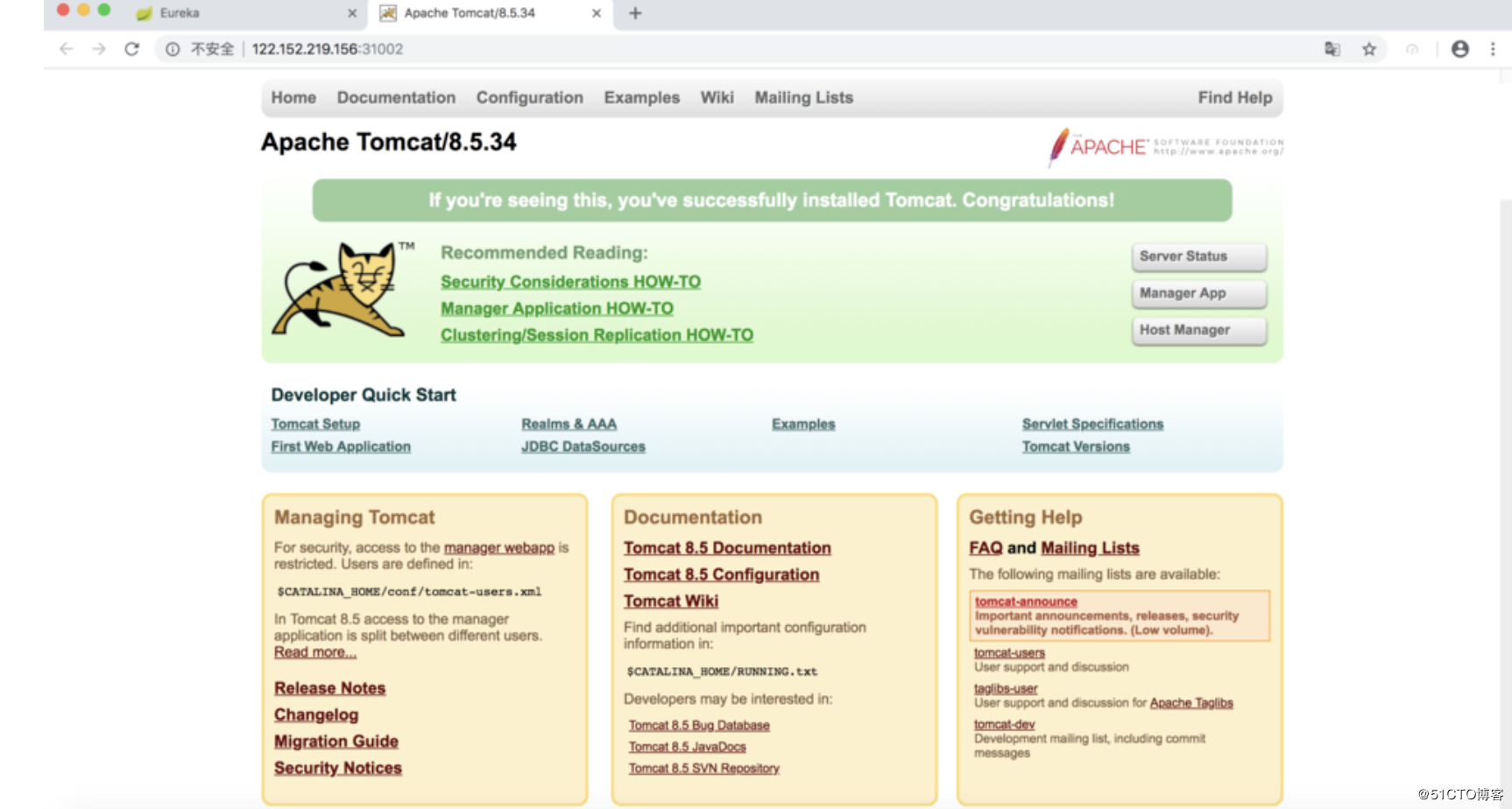
通过NodePort访问Service
NodePort的实现方式是在Kubernetes集群里的每个Node上为需要外部访问的Service开启一个对应的TCP监听端口,外部系统只要用任意一个Node的IP地址+具体的NodePort端口号即可访问此服务,在任意Node上运行netstat命令,我们就可以看到有NodePort端口被监听:
1 | |
但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需要访问此负载均衡器的IP地址,由负载均衡负责转发流量到后面某个Node的NodePort上。
externalIPs
注意事项:对于使用了
externalIPs的Service,当开启IPVS后,externalIP也会作为VIP被ipvs接管,因此如果在externalIp指定的Kubernetes集群中Node节点的IP,需将externalIp替换成预先规划好的VIP(在同一网段找一个未被使用的IP),否则会出现VIP和Node节点IP冲突的问题。使用命令行将VIP绑定到物理网卡上ens192网口,而不是绑定到kube-ipvs0网口
1 | |
1 | |