首先我们要理解:   所有的监控的agent底层最终都是查询的/proc和/sys里的信息推送server端,因为Prometheus Operator收集宿主机信息方面也想用pod跑,会面临到问题node-exporter有选项--path.procfs和--path.sysfs来指定从这俩选项的值的proc和sys读取,容器跑node-exporter只需要挂载宿主机的/proc和/sys到容器fs的某个路径挂载属性设置为readonly后用这两个选项指定即可。
需要看懂本文要具备一下知识点
svc实现原理和会应用以及svc和endpoint关系
了解prometheus(不是operator的)工作机制
知道什么是metrics(不过有了prometheus-operator似乎不是必须)
速补基础 什么是metrics   这里来介绍啥什么是metrics,例如我们要查看etcd的metrics,先查看etcd的运行参数找到相关的值,这里我是kubeadm安装的所以需要查看pod的详细信息,非yml自行查看systemd文件或者运行参数找到相关参数和值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [root@master-1 node-exporter]# kubectl get pod -n kube-system etcd-master-1 -o yaml4 e0989623c0d5b653b7d5f7693d238094 e0989623c0d5b653b7d5f7693d23809"2019-01-22T18:08:00.166244667+08:00" source : file "" "2019-01-22T10:09:31Z" 1 "7304834" /api/ v1/namespaces/ kube-system/pods/ etcd-master-1 1 e2d-11 e9-a8c7-d8490b8af3aefile =/etc/ kubernetes/pki/ etcd/server.crttrue /var/ lib/etcd1 =https:file =/etc/ kubernetes/pki/ etcd/server.key1 file =/etc/ kubernetes/pki/ etcd/peer.crttrue file =/etc/ kubernetes/pki/ etcd/peer.keyfile =/etc/ kubernetes/pki/ etcd/ca.crtcount =10000 file =/etc/ kubernetes/pki/ etcd/ca.crt3.2 .24
我们需要两部分信息
listen-client-urls的httpsurl,我这里是https://172.19.0.203:2379
允许客户端证书信息
然后使用下面的curl,带上各自证书路径访问https的url执行 1 [root@master-1 node-exporter]# curl --cacert /etc/ kubernetes/pki/ etcd/ca.crt --cert / etc/kubernetes/ pki/etcd/ server.crt --key /etc/ kubernetes/pki/ etcd/server.key https:/ /172.19.0.203:2379/m etrics
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ...."RoleList" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"RoleRevokePermission" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"Snapshot" ,grpc_service="etcdserverpb.Maintenance" ,grpc_type="server_stream" } 0"Status" ,grpc_service="etcdserverpb.Maintenance" ,grpc_type="unary" } 0"Txn" ,grpc_service="etcdserverpb.KV" ,grpc_type="unary" } 259160"UserAdd" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"UserChangePassword" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"UserDelete" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"UserGet" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"UserGrantRole" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"UserList" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"UserRevokeRole" ,grpc_service="etcdserverpb.Auth" ,grpc_type="unary" } 0"Watch" ,grpc_service="etcdserverpb.Watch" ,grpc_type="bidi_stream" } 86HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.TYPE process_cpu_seconds_total counterHELP process_max_fds Maximum number of open file descriptors.TYPE process_max_fds gaugeHELP process_open_fds Number of open file descriptors.TYPE process_open_fds gaugeHELP process_resident_memory_bytes Resident memory size in bytes.TYPE process_resident_memory_bytes gaugeHELP process_start_time_seconds Start time of the process since unix epoch in seconds.TYPE process_start_time_seconds gaugeHELP process_virtual_memory_bytes Virtual memory size in bytes.TYPE process_virtual_memory_bytes gauge
同理kube-apiserver也有metrics信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@master-1 node-exporter] # kubectl get --raw /metrics"https://[::1]:6443/apis?timeout=32s" ,verb="GET " ,le="0.512" } 39423 "https://[::1]:6443/apis?timeout=32s" ,verb="GET " ,le="+Inf" } 39423 "https://[::1]:6443/apis?timeout=32s" ,verb="GET " } 24 .781942557999795 "https://[::1]:6443/apis?timeout=32s" ,verb="GET " } 39423 "200" ,host="[::1]:6443" ,method="GET " } 2 .032031e+06 "200" ,host="[::1]:6443" ,method="PUT " } 1 .106921e+06 "201" ,host="[::1]:6443" ,method="POST " } 38 "401" ,host="[::1]:6443" ,method="GET " } 17378 "404" ,host="[::1]:6443" ,method="GET " } 3 .546509e+06 "409" ,host="[::1]:6443" ,method="POST " } 29 "409" ,host="[::1]:6443" ,method="PUT " } 20 "422" ,host="[::1]:6443" ,method="POST " } 1 "503" ,host="[::1]:6443" ,method="GET " } 5 0 0
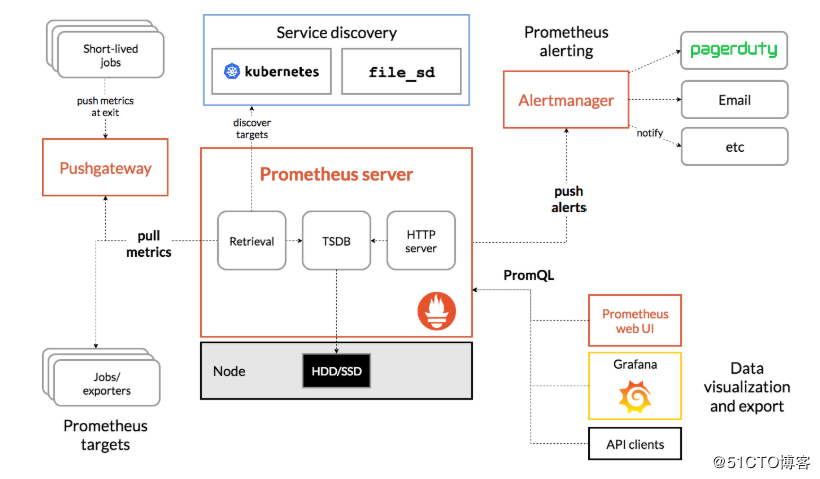
  这种就是prometheus的定义的metrics格式规范,缺省是在http(s)的url的/metrics输出,而metrics要么程序定义输出(模块或者自定义开发),要么用官方的各种exporter(node-exporter,mysqld-exporter,memcached_exporter…)采集要监控的信息占用一个web端口然后输出成metrics格式的信息,prometheus server去收集各个target的metrics存储起来(tsdb)
  用户可以在prometheus的http页面上用promQL(prometheus的查询语言)或者(grafana数据来源就是用)api去查询一些信息,也可以利用pushgateway去统一采集然后prometheus从pushgateway采集(所以pushgateway类似于zabbix的proxy),prometheus的工作架构如下图
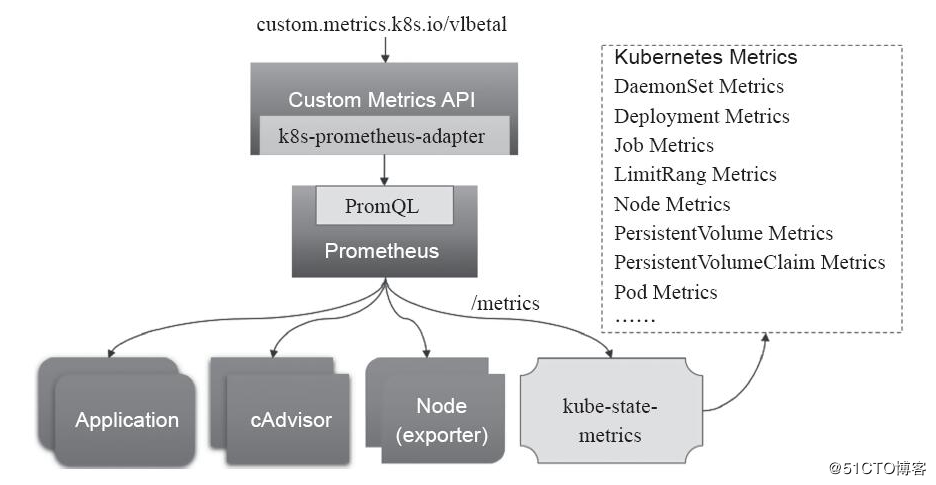
  由于本身prometheus属于第三方的 解决方案,原生的k8s系统并不能对Prometheus的自定义指标进行解析,就需要借助于prometheus的adapter将这些指标数据查询接口转换为标准的Kubernetes自定义指标。(当HPA使用自定义监控指标进行Pod扩容时需要用到adapter)
为什么需要prometheus-operator   由于prometheus是主动去拉取数据,在加上k8s里pod调度的原因导致pod的ip会发生变化,人工不可能去维持,自动发现有基于DNS的,但是新增还是有点麻烦
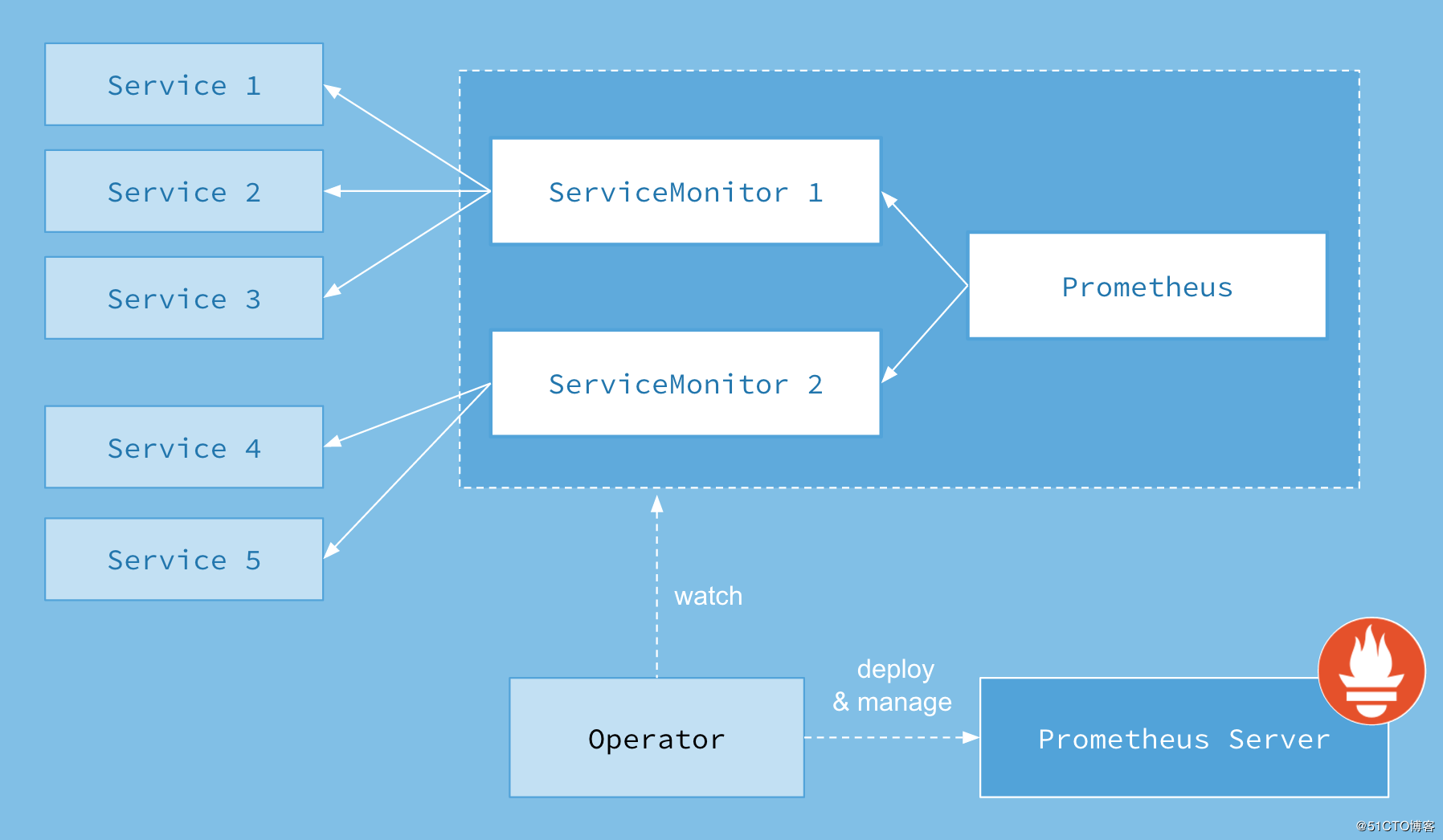
  上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监听并维持这4个资源对象的状态。用户可以利用kind: Prometheus这种声明式创建对应的资源。
这四个CRD作用如下:
Prometheus:由 Operator 依据一个自定义资源kind: Prometheus类型中,所描述的内容是部署的 Prometheus Server 集群,可以将这个自定义资源看作是一种特别用来管理Prometheus Server的StatefulSets资源。
ServiceMonitor:一个Kubernetes自定义资源(和kind: Prometheus一样是CRD),该资源描述了Prometheus Server的Target列表,Operator 会监听这个资源的变化来动态的更新Prometheus Server的Scrape targets并让prometheus server去reload配置(prometheus有对应reload的http接口/-/reload)。而该资源主要通过Selector来依据 Labels 选取对应的Service的endpoints,并让 Prometheus Server 通过 Service 进行拉取(拉)指标资料(也就是metrics信息),metrics信息要在http的url输出符合metrics格式的信息,ServiceMonitor也可以定义目标的metrics的url.
Alertmanager:Prometheus Operator 不只是提供 Prometheus Server 管理与部署,也包含了 AlertManager,并且一样通过一个 kind: Alertmanager 自定义资源来描述信息,再由 Operator 依据描述内容部署 Alertmanager 集群。
PrometheusRule:对于Prometheus而言,在原生的管理方式上,我们需要手动创建Prometheus的告警文件,并且通过在Prometheus配置中声明式的加载。而在Prometheus Operator模式中,告警规则也编程一个通过Kubernetes API 声明式创建的一个资源.告警规则创建成功后,通过在Prometheus中使用想servicemonitor那样用ruleSelector通过label匹配选择需要关联的PrometheusRule即可
部署官方的prometheus-operator 分类文件: 官方的github仓库迁移了,所有yaml转移了,clone部署文件
1 git clone https://gi thub.com/coreos/ kube-prometheus.git
官方把所有文件都放在一起,这里我复制了然后分类下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 mkdir kube-prom 2 root root 4096 Dec 2 09:53 adapter 2 root root 4096 Dec 2 09:53 alertmanager 2 root root 4096 Dec 2 09:53 grafana 2 root root 4096 Dec 2 09:53 kube-state-metrics 2 root root 4096 Dec 2 09:53 node-exporter 2 root root 4096 Dec 2 09:34 operator 2 root root 4096 Dec 2 09:53 prometheus 2 root root 4096 Dec 2 09:53 serviceMonitor 1 root root 60 Dec 2 09:34 0namespace-namespace.yaml 1 root root 274629 Dec 2 09:34 prometheus-operator-0alertmanagerCustomResourceDefinition.yaml 1 root root 12100 Dec 2 09:34 prometheus-operator-0podmonitorCustomResourceDefinition.yaml 1 root root 321507 Dec 2 09:34 prometheus-operator-0prometheusCustomResourceDefinition.yaml 1 root root 14561 Dec 2 09:34 prometheus-operator-0prometheusruleCustomResourceDefinition.yaml 1 root root 17422 Dec 2 09:34 prometheus-operator-0servicemonitorCustomResourceDefinition.yaml 1 root root 425 Dec 2 09:34 prometheus-operator-clusterRoleBinding.yaml 1 root root 1066 Dec 2 09:34 prometheus-operator-clusterRole.yaml 1 root root 1405 Dec 2 09:34 prometheus-operator-deployment.yaml 1 root root 239 Dec 2 09:34 prometheus-operator-serviceAccount.yaml 1 root root 420 Dec 2 09:34 prometheus-operator-service.yaml
有些版本的k8s的label为beta.kubernetes.io/os
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ curl -s https://zhangguanzhang.github.io/bash/label.sh | bash
如果是上面这种没有kubernetes.io/os: linux的情况则需要修改yaml里的selector字段
1 2 3 4 5 6 7 8 $ grep -A1 nodeSelector alertmanager/alertmanager-alertmanager.yaml $ sed -ri '/linux/s#kubernetes.io#beta.&#' \ alertmanager/alertmanager-alertmanager.yaml \ prometheus/prometheus-prometheus.yaml \ node-exporter/node-exporter-daemonset.yaml \ kube-state-metrics/kube-state-metrics-deployment.yaml
quay.io可能不好拉取,这里修改使用Azure的代理或者使用dockerhub上
1 2 3 4 5 6 $ sed -ri '/quay.io/s#quay.io/prometheus#prom#' \ alertmanager/alertmanager-alertmanager.yaml \ prometheus/prometheus-prometheus.yaml \ node-exporter/node-exporter-daemonset.yaml $ find -type f -exec sed -ri 's#k8s.gcr.io#gcr.azk8s.cn/google_containers#' {} \; $ find . -type f -name '*ml' -exec sed -ri 's#quay.io/#quay.azk8s.cn/#' {} \;
部署operator 1 [root@master -1 manifests]# kubectl apply -f operator/
确认状态运行正常再往后执行
1 2 3 [root@master-1 manifests ]# $ kubectl -n monitoring get pod operator -56954 c76b5-qm9ww 1 /1 Running 0 24 s
部署整套CRD 确保prometheus-operator的pod运行起来后就可以,创建相关的CRD,这里镜像可能也要很久,建议提前看下需要拉取哪些镜像提前拉取了
1 2 3 4 5 6 7 kubectl apply -f adapter/apply -f alertmanager/apply -f node-exporter/apply -f kube-state-metrics/apply -f grafana/apply -f prometheus/apply -f serviceMonitor/
部署完成后 1 [root@master -1 manifests]# kubectl - n monitoring get all
常见坑的说明和解决方法 坑一:
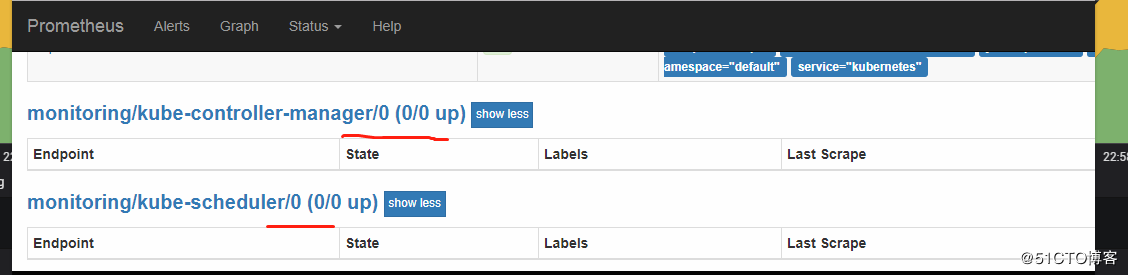
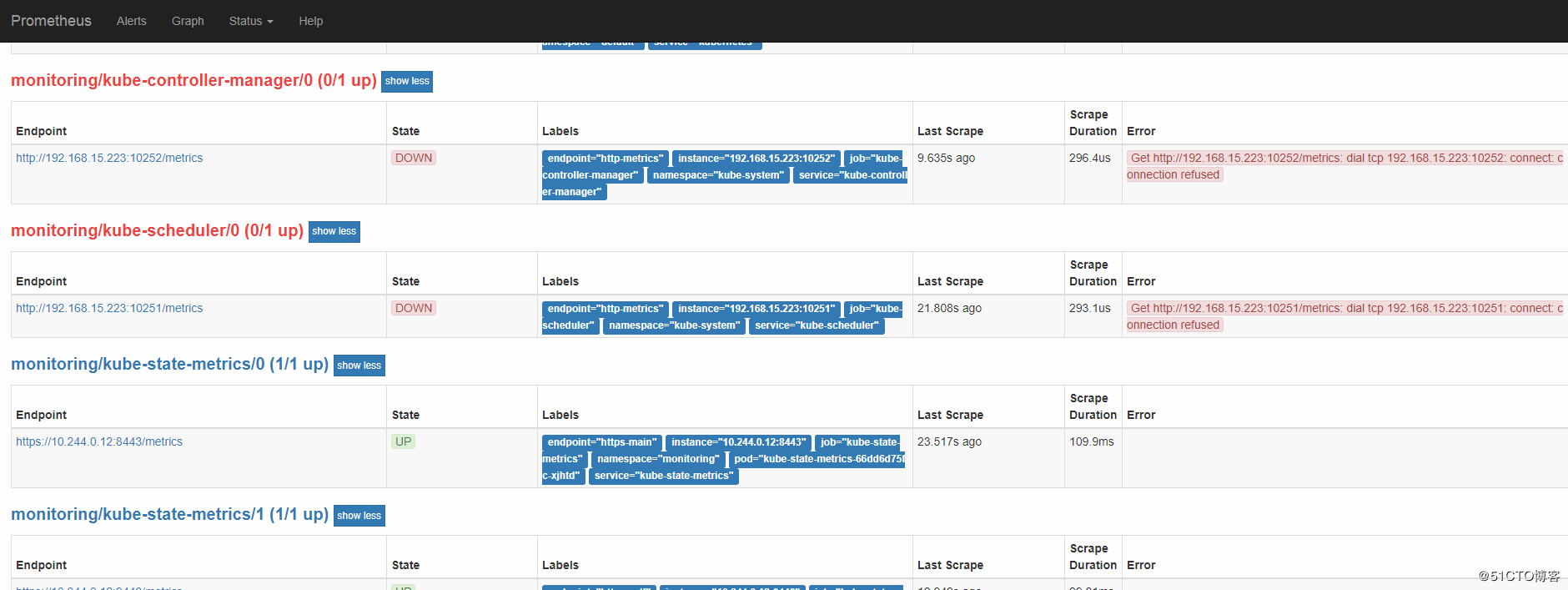
  这里要注意有一个坑,二进制部署k8s管理组件和新版本kubeadm部署的都会发现在prometheus server的页面上发现kube-controller和kube-schedule的target为0/0也就是上图所示。kube-scheduler 组件对应的 ServiceMonitor 资源的定义:(prometheus-serviceMonitorKubeScheduler.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: kube-scheduler name: kube-scheduler namespace: monitoring spec: endpoints: - interval: 30s port: http-metrics jobLabel: k8s-app namespaceSelector: matchNames: - kube-system selector: matchLabels: k8s-app: kube-scheduler
  上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过selector.matchLabels在 kube-system 这个命名空间下面匹配具有k8s-app=kube-scheduler这样的 Service,但是我们系统中根本就没有对应的 Service。
prometheus-serviceMonitorKubeControllerManager.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: kube-controller-manager name: kube-controller-manager namespace: monitoring spec: endpoints: - interval: 30s metricRelabelings: - action: drop regex: etcd_(debugging|disk|request|server).* sourceLabels: - __name__ port: http-metrics jobLabel: k8s-app namespaceSelector: matchNames: - kube-system selector: matchLabels: k8s-app: kube-controller-manager
而kube-system里默认只有这俩svc,且没有符合上面的label 1 2 3 4 [root@master-1 serviceMonitor]# kubectl -n kube-system get svcNAME TYPE CLUSTER -IP EXTERNAL -IP PORT(S) AGE10.96 .0 .10 <none > 53 /UDP,53 /TCP 139 mNone <none > 10250 /TCP 103 m
但是却有对应的ep(没有带任何label)被创建,这点想不通官方什么鬼操作,另外这里没有kubelet的ep,二进制的话会有 1 2 3 4 5 [root@master -1 serviceMonitor]# kubectl get ep - n kube- system - controller- manager < none > 139 m- dns 10.244 .1 .2 :53 ,10.244 .8 .10 :53 ,10.244 .1 .2 :53 + 1 more... 139 m- scheduler < none > 139 m
解决办法   所以这里我们创建两个管理组建的svc,名字无所谓,关键是svc的label要能被servicemonitor选中,svc的选择器的label是因为kubeadm的staticPod的label是这样(注意:如果是二进制部署的这俩svc的selector部分不能要,因为二进制安装kube-controller-manager和kube-scheduler都是外部IP不是Pod运行的,service反代外部IP时不需要写selector但是需要手工创建Endpoints。10251是kube-scheduler组件 metrics 数据所在的端口,10252是kube-controller-manager组件的监控数据所在端口。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager spec: selector: component: kube-controller-manager type: ClusterIP clusterIP: None ports: - name: http-metrics port: 10252 targetPort: 10252 protocol: TCP --- apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-scheduler labels: k8s-app: kube-scheduler spec: selector: component: kube-scheduler type: ClusterIP clusterIP: None ports: - name: http-metrics port: 10251 targetPort: 10251 protocol: TCP
  二进制的话需要我们手动填入svc对应的ep的属性,我集群是HA的,所有有三个,仅供参考,别傻傻得照抄,另外这个ep的名字得和上面的svc的名字和属性对应上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 apiVersion: v1 kind: Endpoints metadata: labels: k8s-app: kube-controller-manager name: kube-controller-manager namespace: kube-system subsets: - addresses: - ip: 172.16 .0 .2 - ip: 172.16 .0 .7 - ip: 172.16 .0 .8 ports: - name: http-metrics port: 10252 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: labels: k8s-app: kube-scheduler name: kube-scheduler namespace: kube-system subsets: - addresses: - ip: 172.16 .0 .2 - ip: 172.16 .0 .7 - ip: 172.16 .0 .8 ports: - name: http-metrics port: 10251 protocol: TCP
  这里不知道为啥kubeadm部署的没有kubelet这个ep,我博客二进制部署后是会有kubelet这个ep的,下面仅供参考,IP根据实际写。另外kubeadm部署下kubelet的readonly的metrics端口(默认是10255)不会开放可以删掉ep的那部分port
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 apiVersion: v1 kind: Endpoints metadata: labels: k8s-app: kubelet name: kubelet namespace: kube-system subsets: - addresses: - ip: 172.16 .0 .14 targetRef: kind: Node name: k8s-n2 - ip: 172.16 .0 .18 targetRef: kind: Node name: k8s-n3 - ip: 172.16 .0 .2 targetRef: kind: Node name: k8s-m1 - ip: 172.16 .0 .20 targetRef: kind: Node name: k8s-n4 - ip: 172.16 .0 .21 targetRef: kind: Node name: k8s-n5 ports: - name: http-metrics port: 10255 protocol: TCP - name: cadvisor port: 4194 protocol: TCP - name: https-metrics port: 10250 protocol: TCP
坑二   访问prometheus server的web页面我们发现即使创建了svc和注入对应ep的信息在target页面发现prometheus server请求被拒绝
  在宿主机上我们发现127.0.0.1才能访问,网卡ip不能访问(这里需要注意的是:这里的IP是取自其他项目的IP,所以ip是192不是上面的我们看到的172,我们只是为了演示这个现象。)
1 2 3 4 5 6 7 8 9 10 11 [root@master-1 serviceMonitor]# hostname -i 192.168 .15.223 1 serviceMonitor]# curl -I http: 7 ) Failed connect to 192.168 .15.223 :10251 ; Connection refused1 serviceMonitor]# curl -I http: 1.1 200 OK30349 Type : text /plain; version=0.0 .4 Date : Mon, 07 Jan 2019 13 :33 :50 GMT
解决办法 修改管理组件bind的ip,如果使用kubeadm启动的集群,初始化时的config.yml里可以加入如下参数
1 2 3 4 controllerManagerExtraArgs: address: 0.0 .0 .0 schedulerExtraArgs: address: 0.0 .0 .0
已经启动后的使用下面命令更改就会滚动更新
1 sed -ri '/--address/s#=.+#=0.0.0.0#' /etc/ kubernetes/manifests/ kube-*
二进制的话查看是不是bind的0.0.0.0如果不是就修改成0.0.0.0
坑三   默认serviceMonitor实际上只能选三个namespacs,默认和Kube-system和monitoring,见文件cat prometheus-roleSpecificNamespaces.yaml,需要其他的ns自行创建role
访问相关页面   通过浏览器查看prometheus.monitoring.k8s.local与grafana.monitoring.k8s.local是否正常,若沒问题就可以看到下图结果,grafana初始用户名和密码是admin。
部署kind: Prometheus (以下均为扩展知识) 现在我们有了prometheus这个CRD,我们部署一个prometheus server只需要如下声明即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ cat<<EOF | kubectl apply -f - apiVersion: v1 kind: ServiceAccount metadata: name: prometheus --- apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: name: prometheus spec: serviceMonitorSelector: matchLabels: team: frontend serviceAccountName: prometheus resources: requests: memory: 400Mi EOF
上面要注意的是我创建prometheus server的时候有如下值
1 2 3 serviceMonitorSelector: matchLabels: team: frontend
  该值字面意思可以知道就是指定prometheus server去选择哪些ServiceMonitor,这个概念和svc去选择pod一样,可能一个集群跑很多prometheus server来监控各自选中的ServiceMonitor,如果想一个prometheus server监控所有的则spec.serviceMonitorSelector: {}为空即可,而namespaces的范围同样的设置spec.serviceMonitorNamespaceSelector: {},官方的prometheus实例里我们可以看到设置了这两个值(prometheus-prometheus.yaml)。
给prometheus server设置相关的RBAC权限
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 $ cat<<EOF | kubectl apply -f - apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: ["" ]resources: - nodes - services - endpoints - pods verbs: ["get" , "list" , "watch" ]- apiGroups: ["" ]resources: - configmaps verbs: ["get" ]- nonResourceURLs: ["/metrics" ]verbs: ["get" ]--- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: default EOF
部署一组pod及其svc 因为service是prometheus operator监控的最小单位,要监控一个svc下的pod的metrics就声明创建一个servicemonitors即可;
首先,我们部署一个带metrics输出的简单程序的deploy,该镜像里的主进程会在8080端口上输出metrics信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ cat<<EOF | kubectl apply -f - apiVersion: extensions/v1beta1 kind: Deployment metadata: name: example-app spec: replicas: 3 template: metadata: labels: app: example-app spec: containers: - name: example-app image: zhangguanzhang/instrumented_app ports: - name: web containerPort: 8080 EOF
创建对应的svc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ cat<<EOF | kubectl apply -f - kind: Service apiVersion: v1 metadata: name: example-app labels: app: example-app spec: selector: app: example-app ports: - name: web port: 8080 EOF
部署kind: ServiceMonitor 现在创建一个ServiceMonitor来告诉prometheus server需要监控带有label app: example-app的svc背后的一组pod的metrics
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ cat<<EOF | kubectl apply -f - apiVersion : monitoring.coreos.com/v1 kind : ServiceMonitor metadata : name : example-app labels : team : frontend spec : selector : matchLabels : app : example-app endpoints : - port: web
默认情况下ServiceMonitor和监控对象必须是在相同Namespace下的,如果要关联非同ns下需要下面这样设置值
1 2 3 4 spec : namespaceSelector : matchNames : - target_ns_name
如果希望ServiceMonitor可以关联任意命名空间下的标签,则通过以下方式定义:
1 2 3 spec: namespaceSelector: any: true
如果需要监控的Target对象启用了BasicAuth认证,那在定义ServiceMonitor对象时,可以使用endpoints配置中定义basicAuth如下所示basicAuth中的password和username值来源于同ns下的一个名为basic-auth的Secret
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 spec endpoints: - basicAuth: password: name: basic-auth key: password username: name: basic-auth key: user port: web --- apiVersion: v1 kind: Secret metadata: name: basic-auth type: Opaque data: user: dXNlcgo= password: cGFzc3dkCg==