我们在使用Prometheus过程中,随着时间的推移,存储在 Prometheus 中的监控指标数据越来越多,查询的频率也在不断的增加,当我们用 Grafana 添加更多的 Dashboard 的时候,可能慢慢地会体验到 Grafana 已经无法按时渲染图表,并且偶尔还会出现超时的情况,特别是当我们在长时间汇总大量的指标数据的时候,Prometheus 查询超时的情况可能更多了,这时就需要用到Prometheus的记录规则(Recording rule)功能,它能够于以类似批处理任务的方式在后台周期性的执行并记录查询结果;(预先运行频繁被用到的或表达式较为复杂计算消耗较大的时候,他可以周期性的运行这个表达式,并将其结果保存为一组新的时间序列; 当需要查询的时候直接会返回已经计算好的结果,这样会比直接查询快,同时也减轻了PromQL的计算压力,同时对可视化查询的时候也很有用,可视化展示每次只需要刷新重复查询相同的表达式即可。)
实现metrics持久化查询
注意:写表达式的时候先在prometheus页面执行一下避免有错误
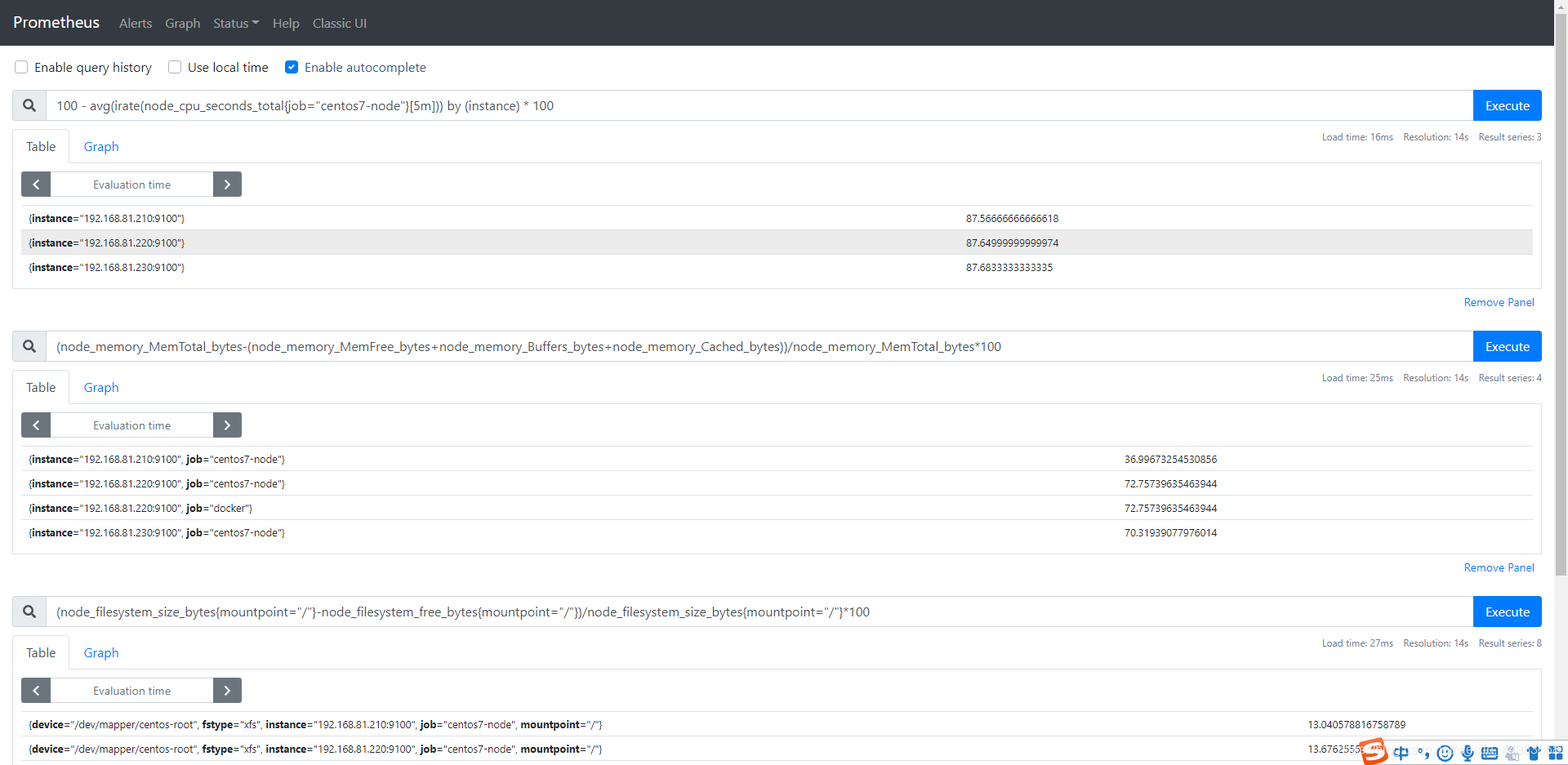
配置prometheus持久化查询配置文件路径
1
2
3
4
5
6
7
8
9
10
| 1.修改配置文件
[root@prometheus-server ~]# vim /etc/prometheus/prometheus.yml
rule_files:
- "rules/node_rules.yml" #指定持久化文件所在路径即可
2.刷新配置文件
[root@prometheus-server ~]# curl -XPOST 127.0.0.1:9090/-/reload
level=info ts=2020-12-25T03:27:28.995Z caller=main.go:871 msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
level=info ts=2020-12-25T03:27:31.031Z caller=main.go:902 msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=2.035652721s remote_storage=3.749µs web_handler=461ns query_engine=999ns scrape=2.033827361s scrape_sd=291.259µs notify=102.034µs notify_sd=67.854µs rules=195.703µs
|
实现CPU使用率持久化查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 1.创建持久化文件
[root@prometheus-server ~]# cd /etc/prometheus/
[root@prometheus-server prometheus]# mkdir rules
2.编写CPU使用率持久化文件
[root@prometheus-server prometheus]# vim rules/node_rules.yml
groups:
- name: node_rules
interval: 10s
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg (irate(node_cpu_seconds_total{job="centos7-node",mode="idle"}[5m])) by (instance) * 100
labels:
metric_type: aggregation
3.加载配置文件
[root@prometheus-server prometheus]# curl -XPOST 127.0.0.1:9090/-/reload
|
解释:
1
2
3
4
5
6
7
| groups:
- name: node_rules //持久化查询的名称
interval: 10s //10s刷新一次,如果不设置就是就是全局中的 evaluation_interval 时间
rules: //记录规则清单,一个rules下面可以写多个记录规则
- record: instance:node_cpu:avg_rate5m //持久化记录查询名称
expr: //取值表达式
labels: //定义一个标签
|
上面的规则其实就是根据 record 规则中的定义,Prometheus 会在后台完成 expr 中定义的 PromQL 表达式周期性运算(每隔10s一次),以 instance 为维度使用 avg 聚合运算符,计算函数 irate 对 node_cpu_seconds_total 指标区间 5m 内的CPU使用率,并且将计算结果保存到新的时间序列 instance:node_cpu:avg_rate5m 中, 同时还可以通过 labels 为样本数据添加额外的自定义标签,但是要注意的是这个 Lables 一定存在当前表达式 Metrics 中。
页面查看 rules 可以看到我们刚刚配置rule规则

点击图上的record名称即可跳转到查询页面
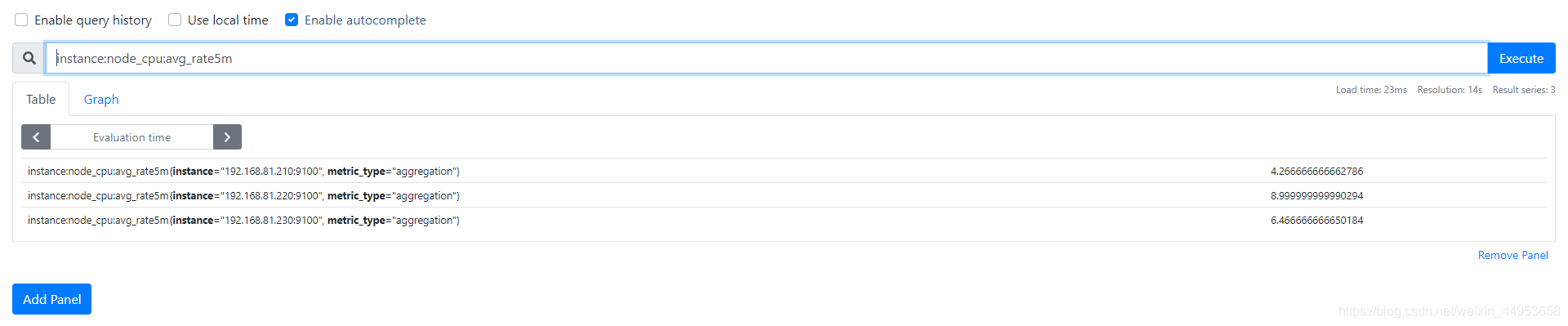
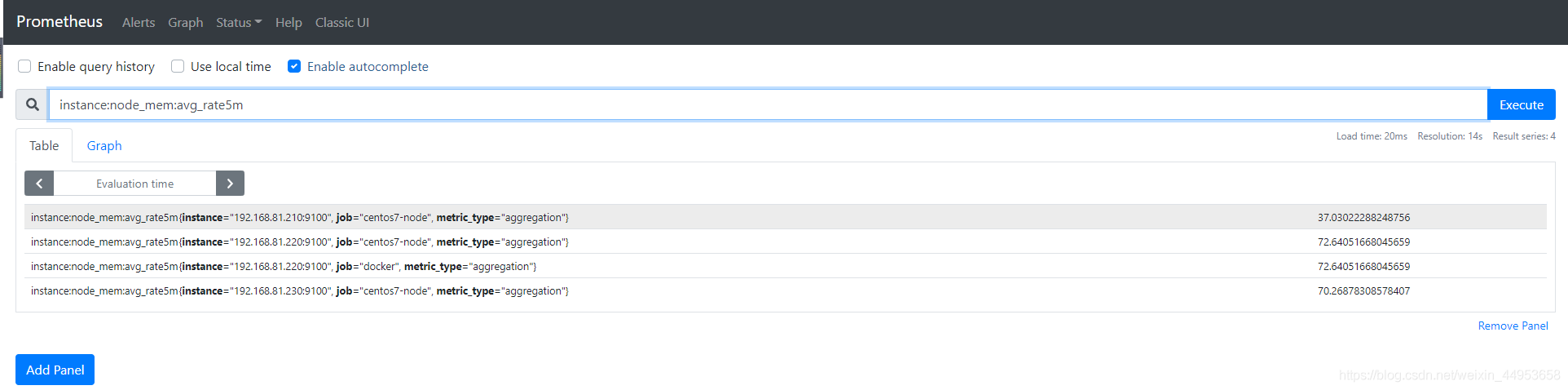
实现内存使用率持久化查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| 1.增加内存持久化配置
[root@prometheus-server prometheus]
groups:
- name: node_rules
interval: 10s
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg(irate(node_cpu_seconds_total{job="centos7-node"}[5m])) by (instance) * 100
labels:
metric_type: aggregation
- record: instance:node_mem:avg_rate5m
expr: (node_memory_MemTotal_bytes-(node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes))/node_memory_MemTotal_bytes * 100
labels:
metric_type: aggregation
2.加载配置
[root@prometheus-server prometheus]
|
查询界面 rules 可以看到我们刚刚配置rule规则
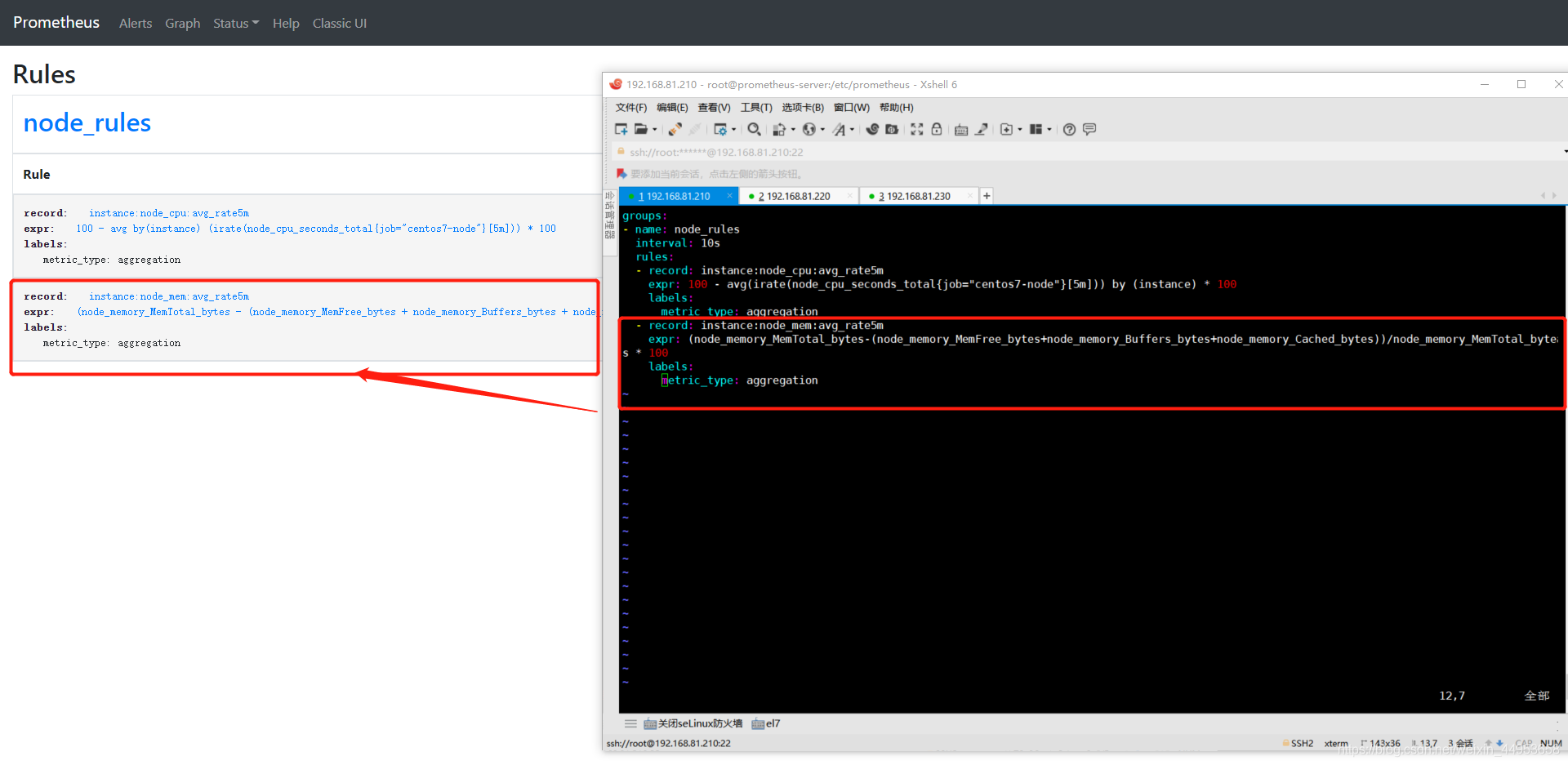
点击图上的record名称即可跳转到查询页面
实现磁盘使用率持久化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| 1.增加内存持久化配置
[root@prometheus-server prometheus]
groups:
- name: node_rules
interval: 10s
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg(irate(node_cpu_seconds_total{job="centos7-node"}[5m])) by (instance) * 100
labels:
metric_type: aggregation
- record: instance:node_mem:avg_rate5m
expr: (node_memory_MemTotal_bytes-(node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes))/node_memory_MemTotal_bytes * 100
labels:
metric_type: aggregation
- record: instance:node_disk:avg_rate5m
expr: (node_filesystem_size_bytes-node_filesystem_free_bytes)/node_filesystem_size_bytes*100
labels:
metric_type: aggregation
2.加载配置
[root@prometheus-server prometheus]
|
查询界面 rules 可以看到我们刚刚配置rule规则
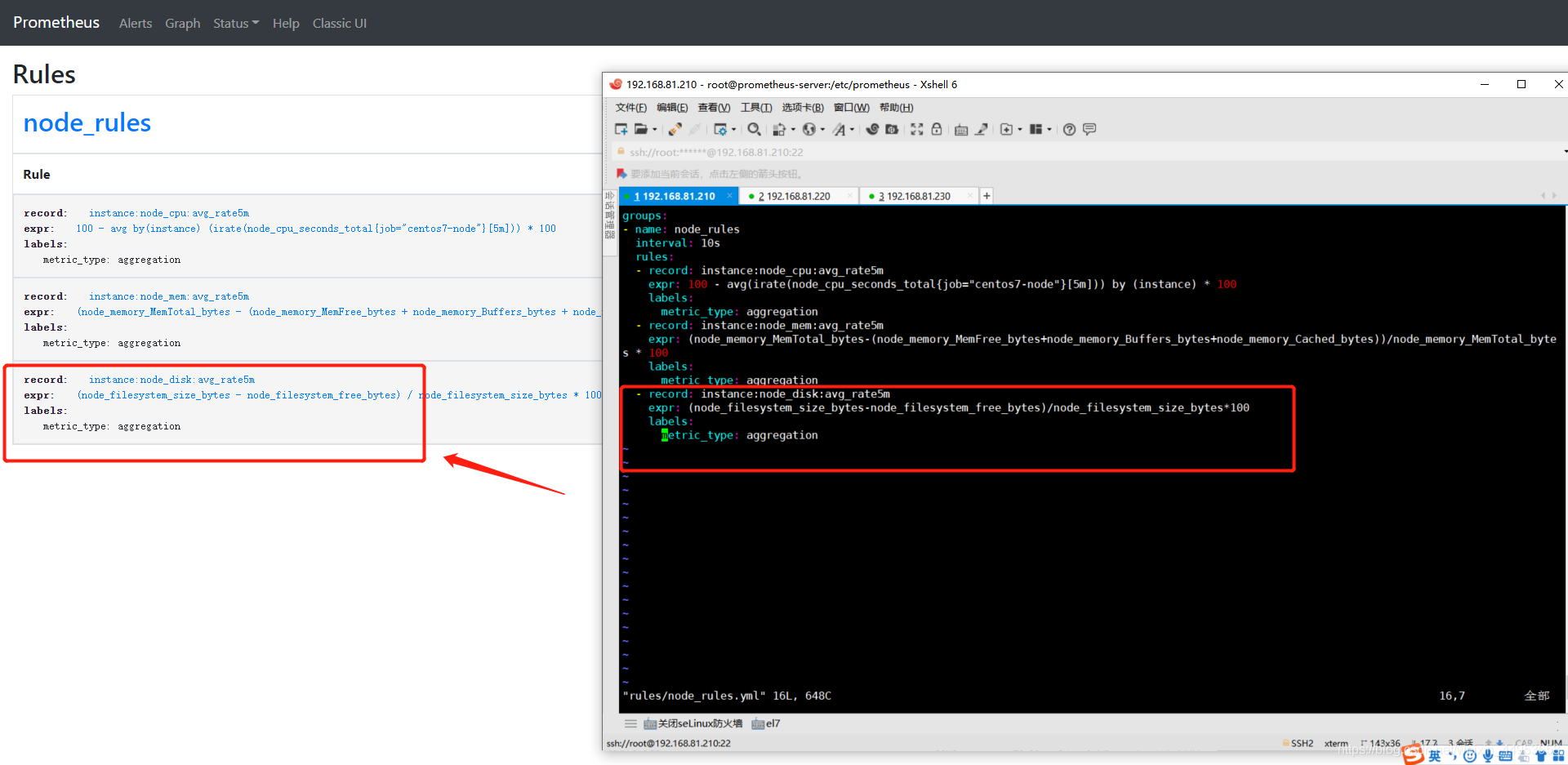
点击图上的record名称即可跳转到查询页面
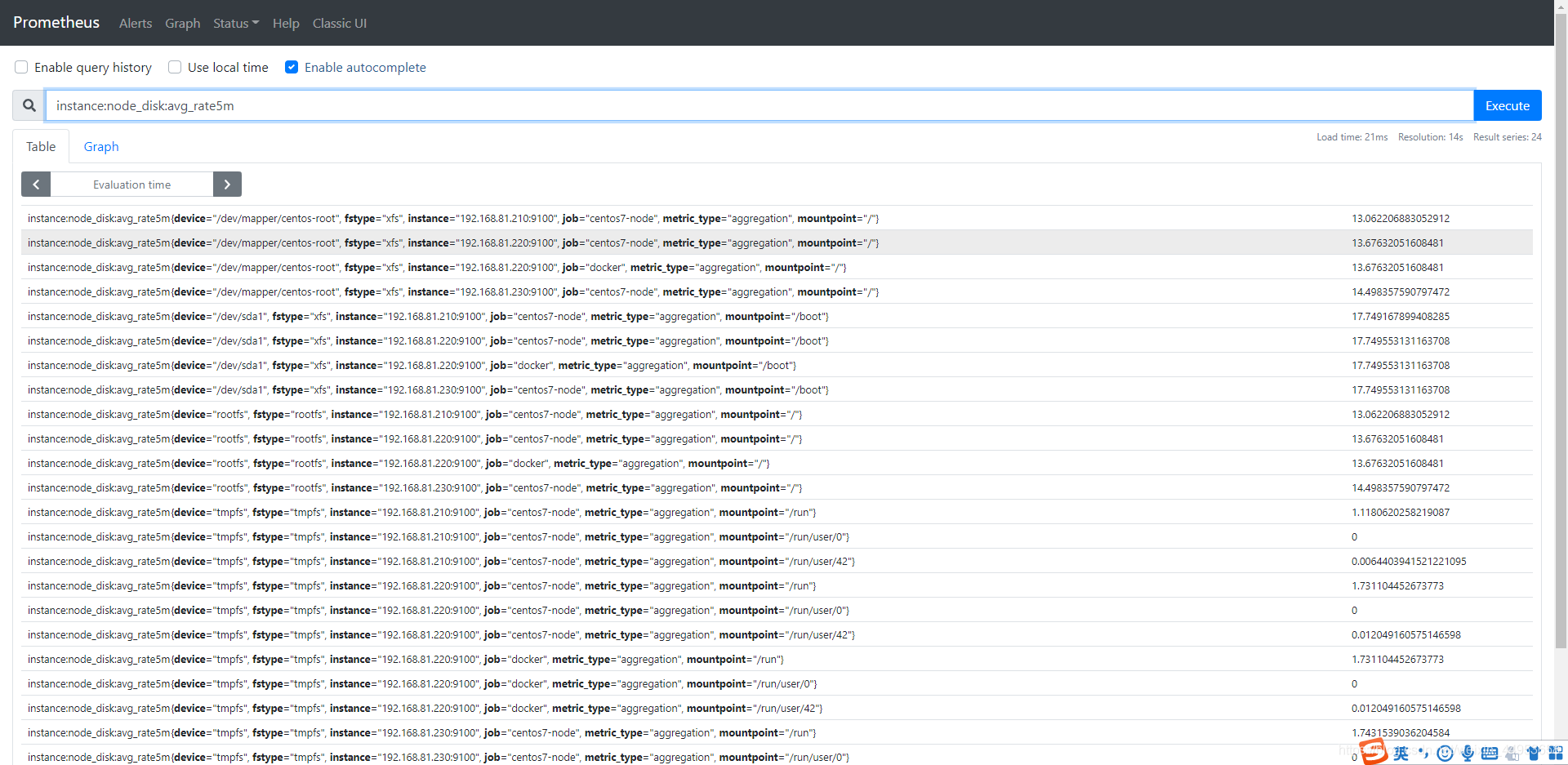
细节
1
2
3
4
| global:
scrape_interval: 2m
scrape_timeout: 10s
evaluation_interval: 4m
|
scrape_interval 这个时间和 evaluation_interval 时间不冲突。scrape_interval 这个是采集时间,evaluation_interval 这时间是在记录规则的时候多久执行一次promql的时间。用户在点 Grafana 中的 Dashboard 的时候他会去执行后面的Promql。如果你点的时候在去计算对于一些运算复杂度高的可能耗时会很久,如果你在grafana中promql的语句写的是记录规则中的record名字,那么他获取到的数据就是已经计算好的结果。这个结果可能是几分钟以前的。
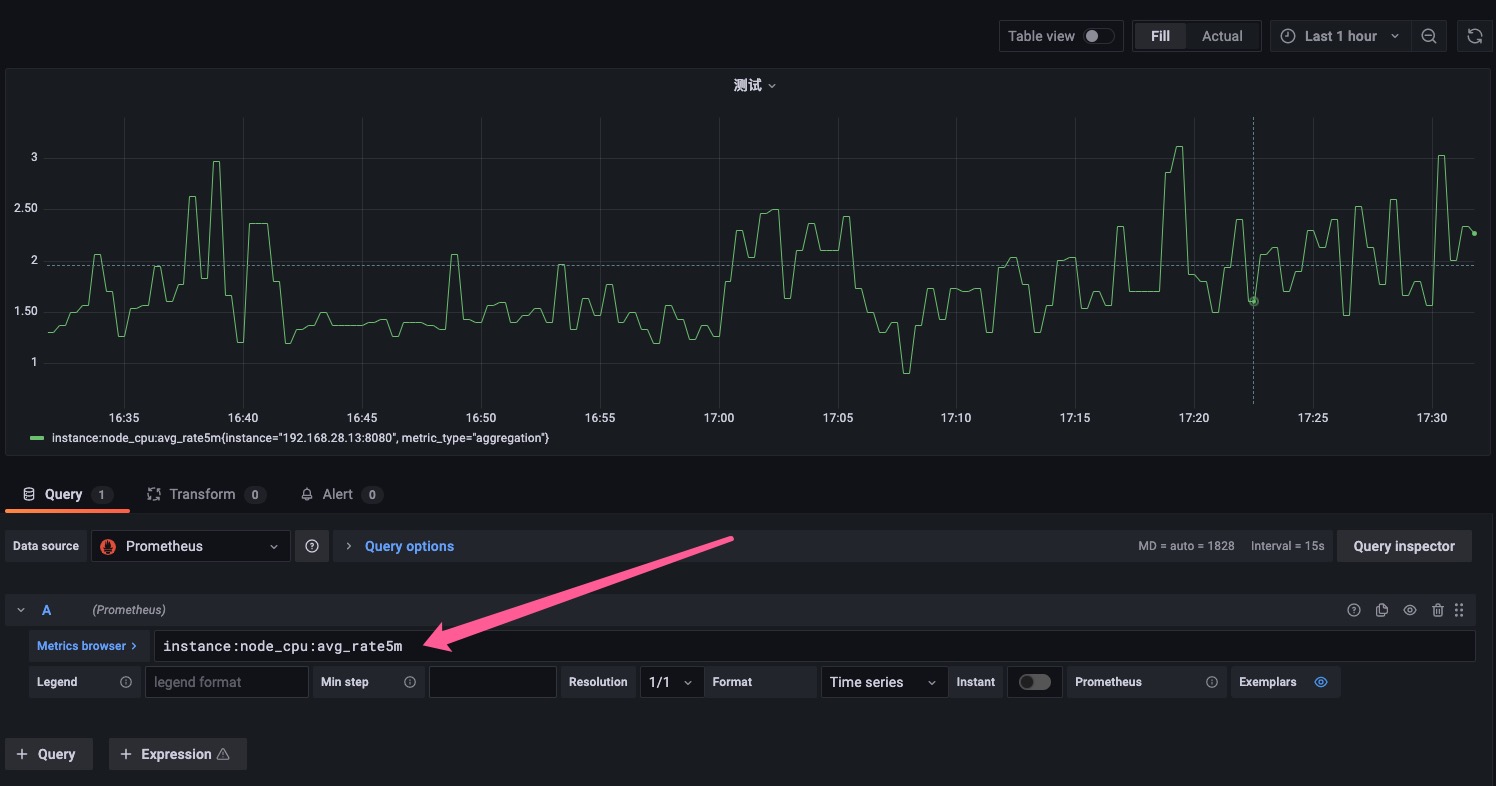
sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_rate{cluster="$cluster", node="$node"}) by (pod) 也可以对他做运算也是可以的。
Grafana安装及配置
Grafana是一款基于go语言开发的通用可视化工具,默认监听于TCP协议的3000端口,支持集成其他认证服务,且自身也通过3000端口/metricsURL输出内建指标;支持从多种不同的数据源加载并展示数据,可作为其数据源的部分存储系统如下所示
- TSDB:Prometheus、IfluxDB、OpenTSDB和Graphit
- 日志和文档存储:Loki和ElasitchSearch
- 分布式请求跟踪:Zipkin、Jaeger和Tempo
- SQL DB: MySQL、PostgreSQL和Microsoft SQL Server
部署Grafana
1
2
| [root@k8s-m1 ~]# wget https://repo.huaweicloud.com/grafana/8.0.3/grafana-8.0.3-1.x86_64.rpm
[root@k8s-m1 ~]# yum -y localinstall grafana-8.0.3-1.x86_64.rpm
|
启动服务器
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@k8s-m1 ~]
[root@k8s-m1 ~]
[root@k8s-m1 ~]
/etc/grafana/grafana.ini
|
Grafana的数据源
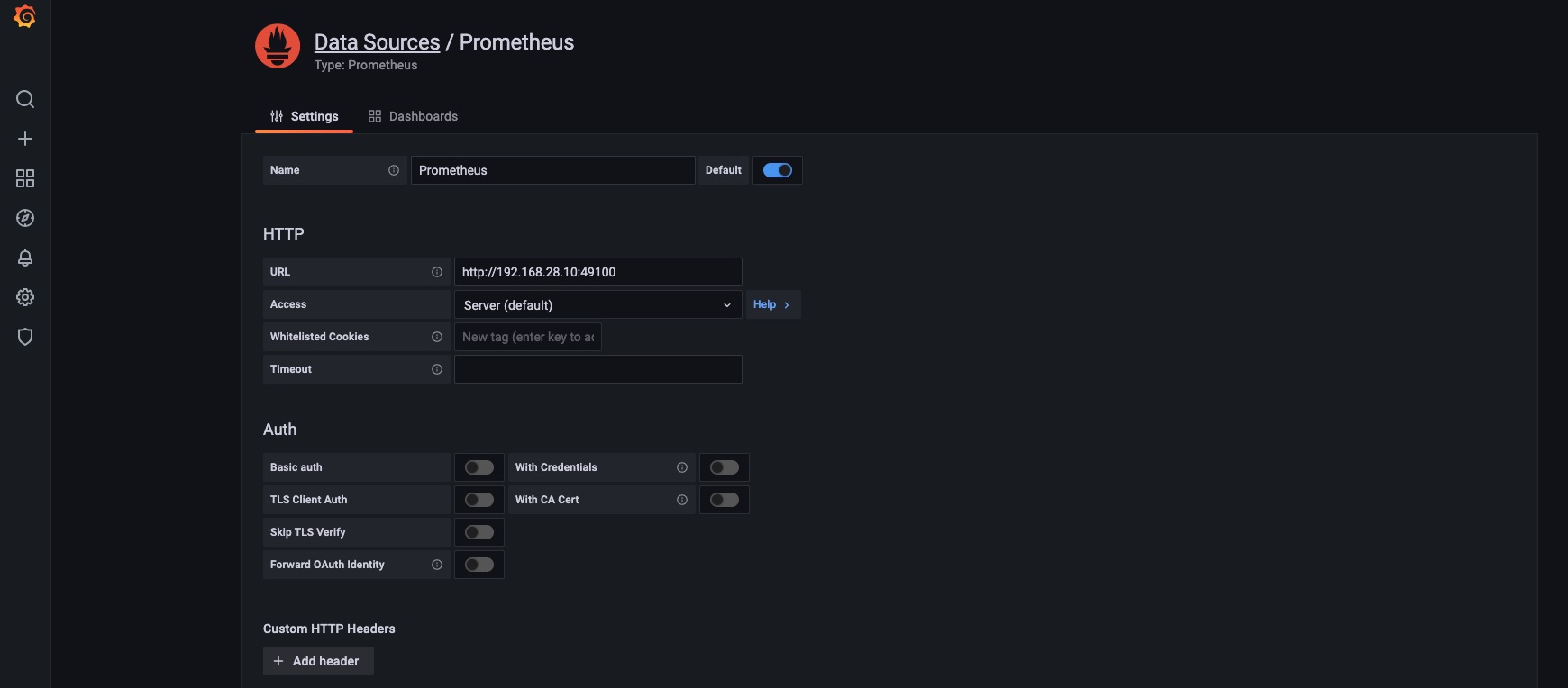
导入内建的Dashboard
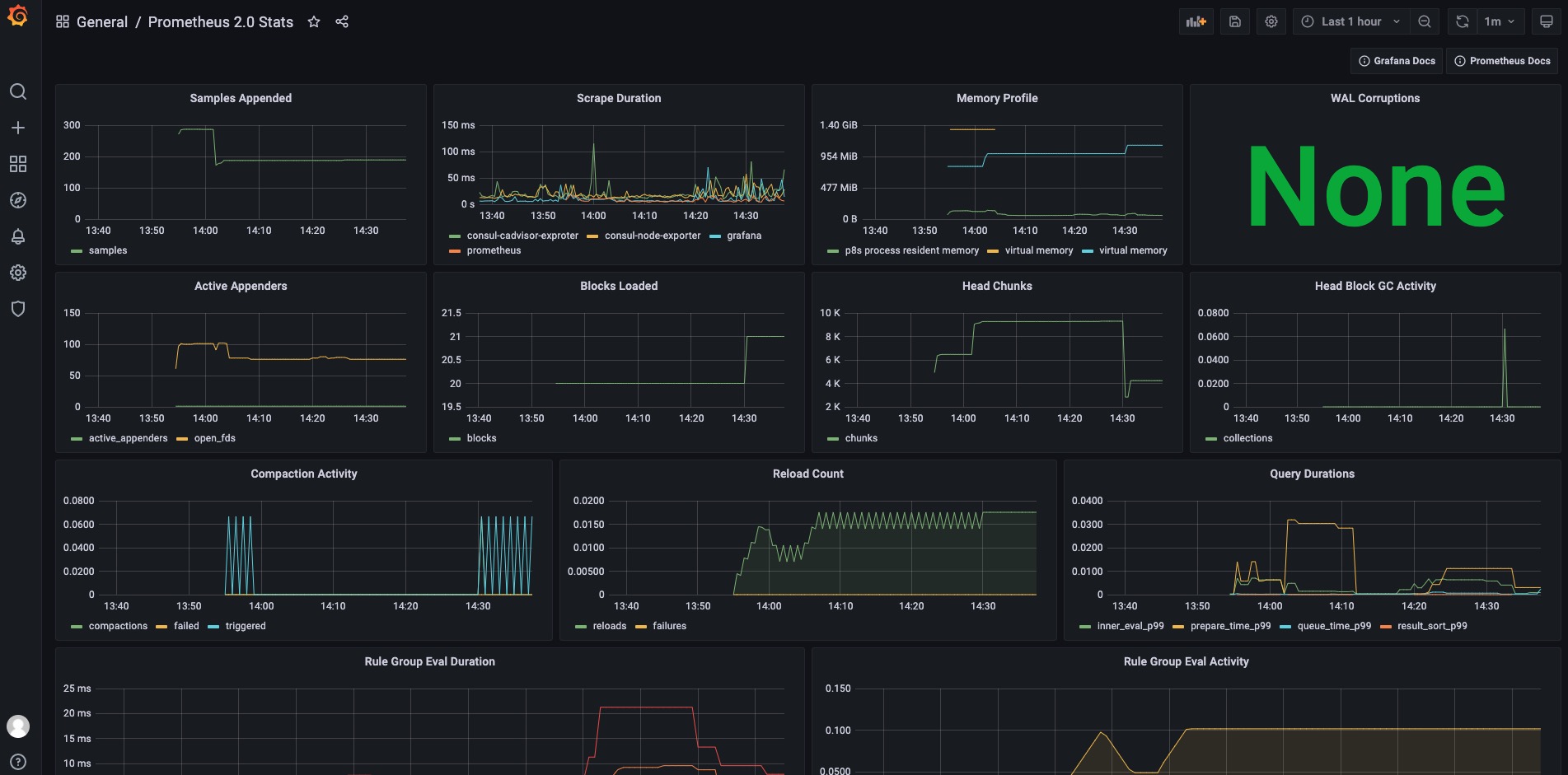
Grafana Dashboard示例
注意
在导入Dashboard后可能有一些显示无数据,我们需要单独创建两个job,一般是因为模板中PromQL里面用到的标签原因,例如:sum(prometheus_tsdb_head_active_appenders{job="prometheus"})
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| - job_name: 'grafana'
consul_sd_configs:
- server: "192.168.28.10:8500"
- server: "192.168.28.11:8500"
- server: "192.168.28.12:8500"
datacenter: 'dc1'
services: []
relabel_configs:
- source_labels: [__meta_consul_service_id]
regex: ".*grafana.*"
action: keep
- job_name: 'prometheus'
consul_sd_configs:
- server: "192.168.28.10:8500"
- server: "192.168.28.11:8500"
- server: "192.168.28.12:8500"
datacenter: 'dc1'
services: []
relabel_configs:
- source_labels: [__meta_consul_service_id]
regex: ".*prometheus.*"
action: keep
|
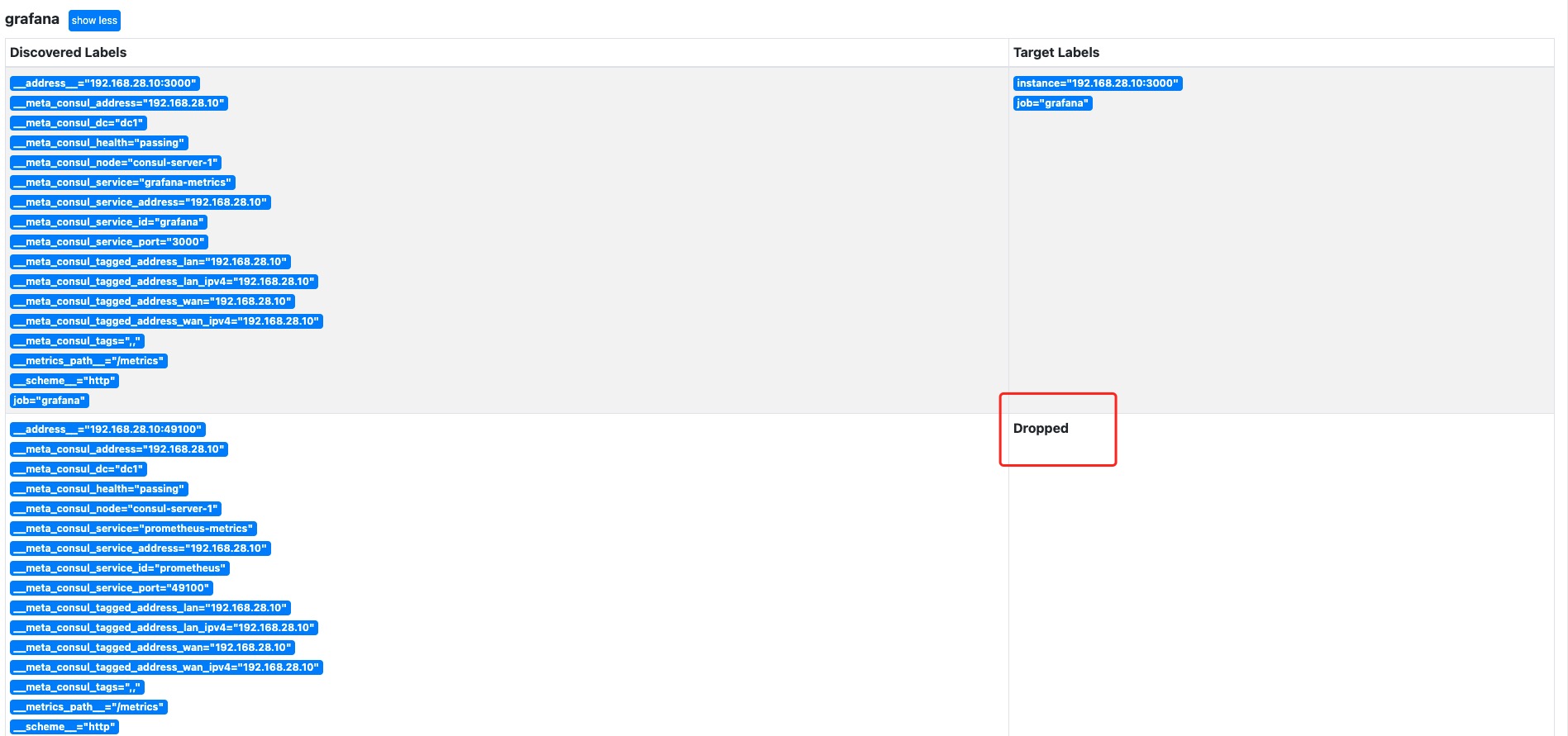
在Consul注册后如果发现Prometheus中没有发现Target,那么可以点一下Service Discovery,然后随便点一个看看是不是被Dropped掉了,如果是那么要看Prometheus.yaml中的relabel_configs是怎么写的。
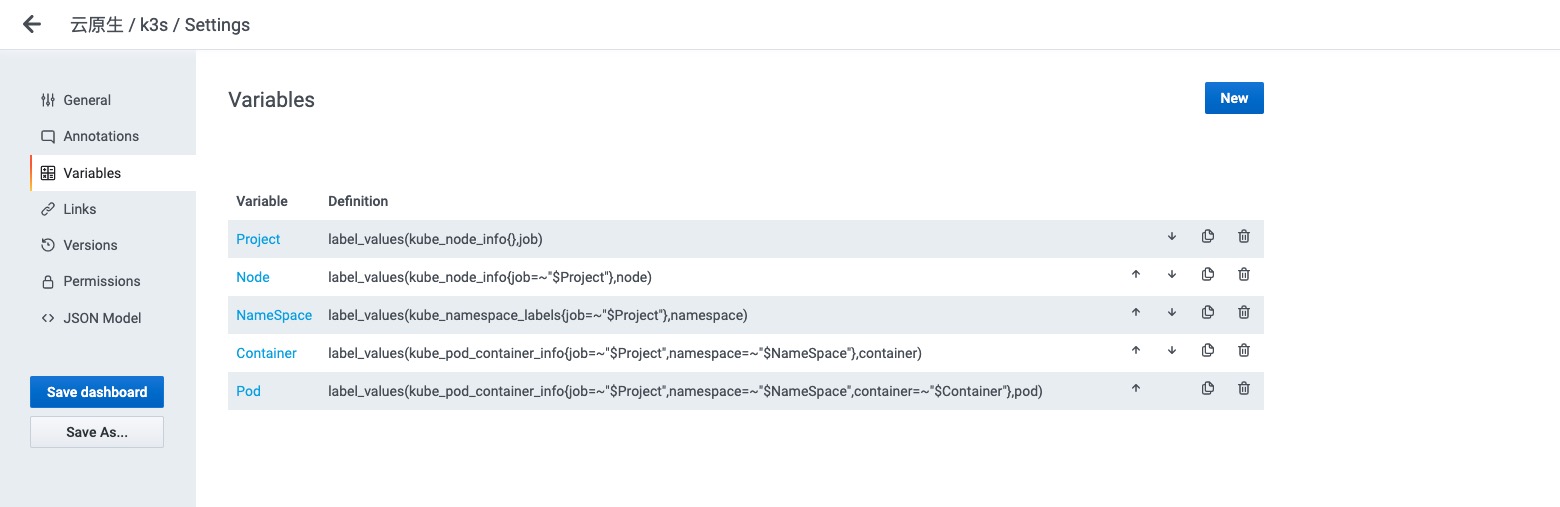
Grafana变量设置
- Name: 变量的名称 (查询时需要使用)
- Type: 变量类型(7种类型,最常用的是Query类型)
- Label: 显示的标签 ( 没有实质作用,就是一个Label)
- Query: 如何找到这个变量的值,怎么获取 (重要,后面写个例子)
- Regex: 这里的正则表达式是对Query的结果在一次处理,然后在赋值给env变量
- Sort: 如何对变量的值进行排序
- Refresh: 什么时候刷新这个变量的值
- On Dashboard Load:面板加载的时候,刷新一次
- On Time Range Change:跟随面板刷新时间刷新该变量,面板的刷新设置在面板的右上角
grafana里prometheus查询语法
| 名称 |
描述 |
| label_values(label) |
返回Promthues中标签名为label的值 |
| label_values(metric, label) |
返回Promthues中metric指标,标签名为label的值 |
| metrics(metric) |
返回所有指标名称满足metric定义正则表达式的指标名称 |
| query_result(query) |
返回prometheus查询语句的查询结果 |
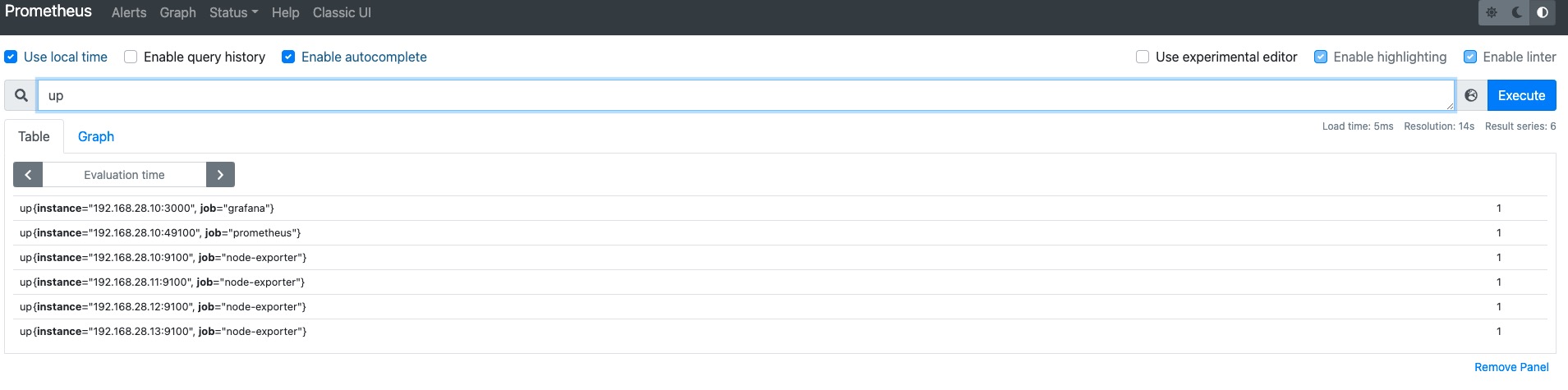
示例1
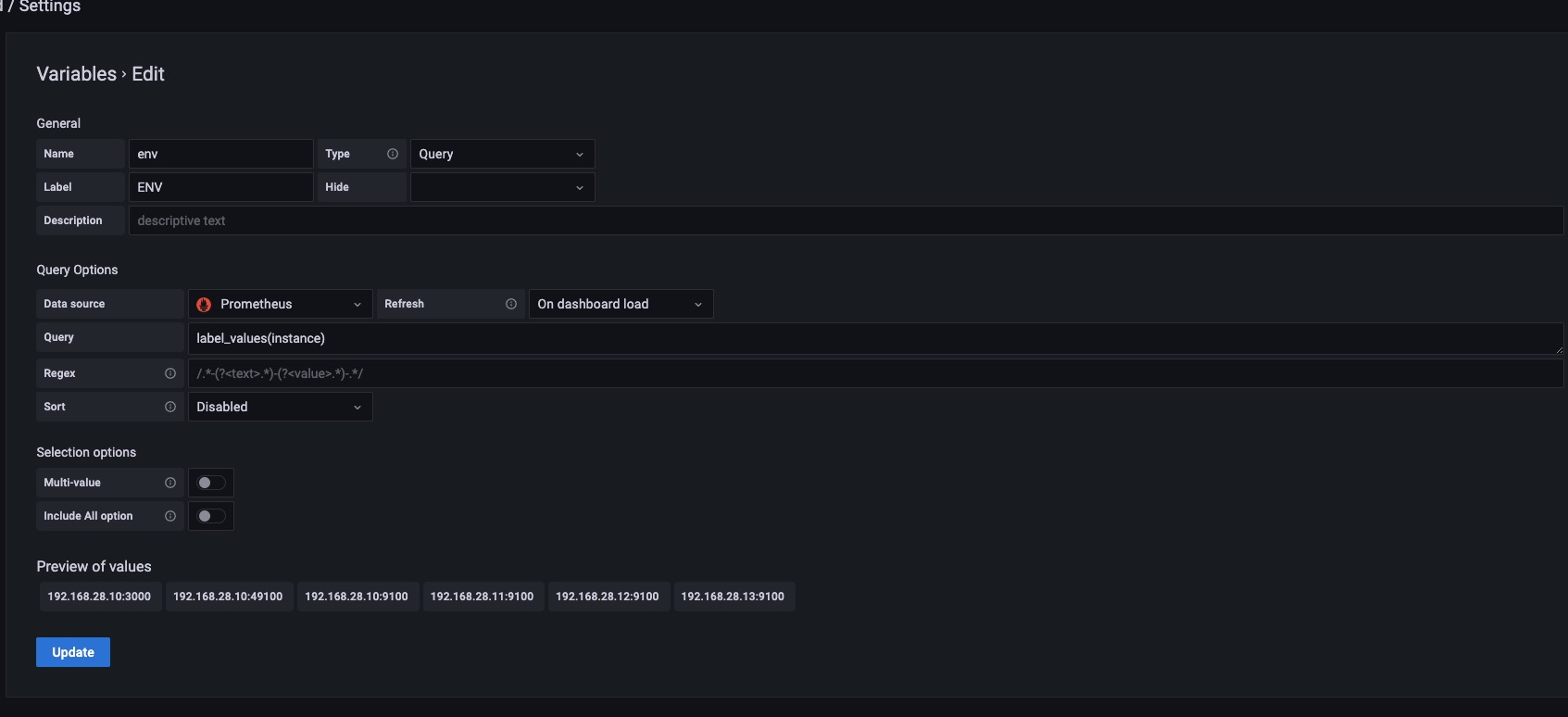
如上图所示,我们设置label_values(instance) 这样只要Prometheus中包含instance这个标签的值都会赋值给env这个变量。如果instance标签中的值有相同的则显示一个。
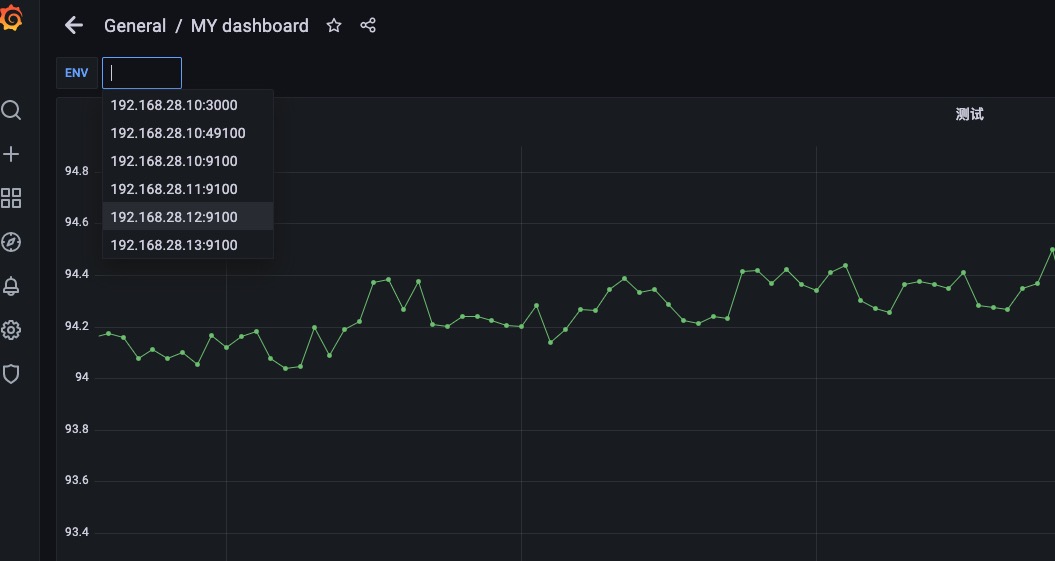
示例2
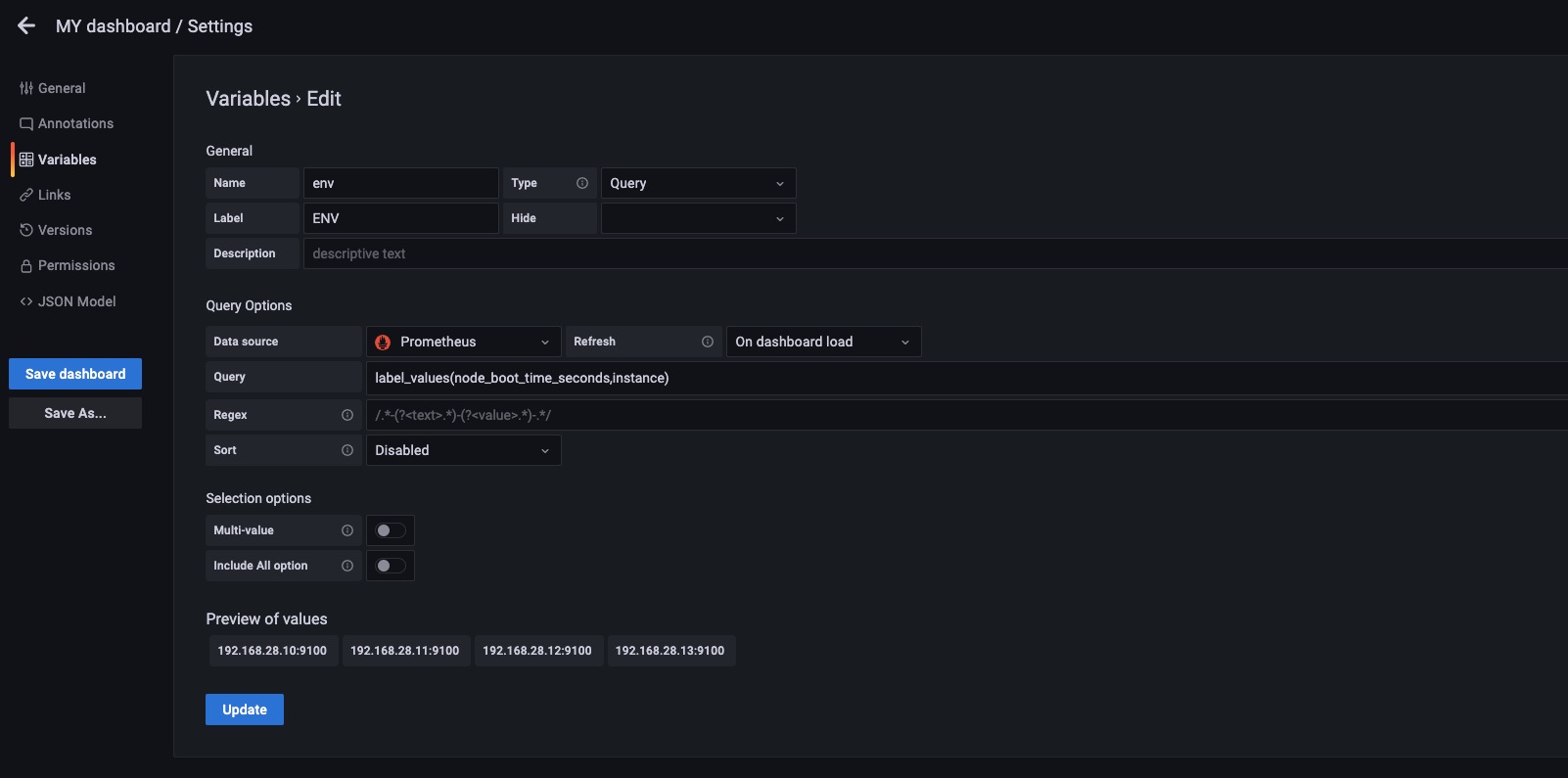
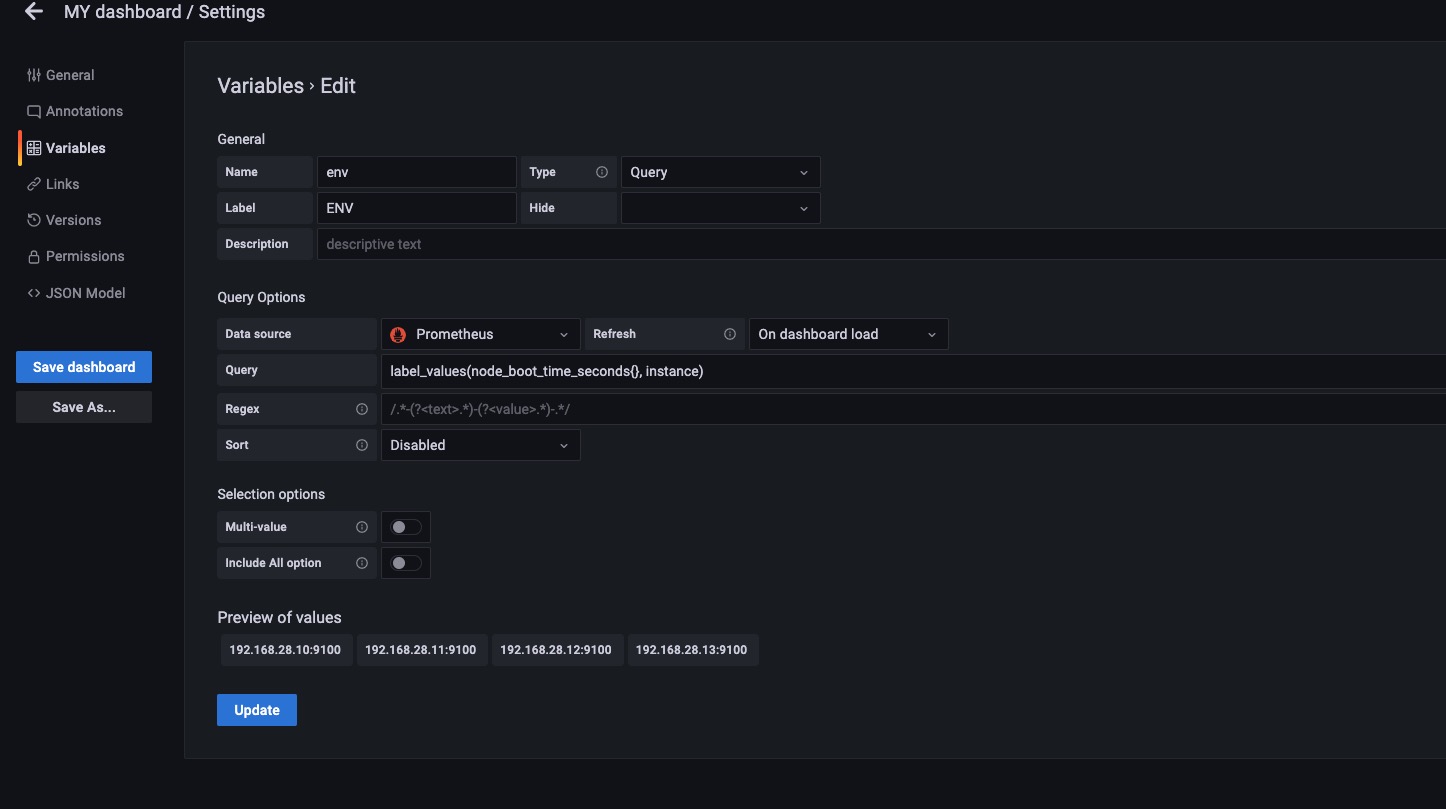
如上图所示,我们设置label_values(node_boot_time_seconds{},instance) 这样设置是将node_boot_time_seconds这个指标名中的标签为instance的值赋值给env变量,如果instance标签中的值有相同的则显示一个。
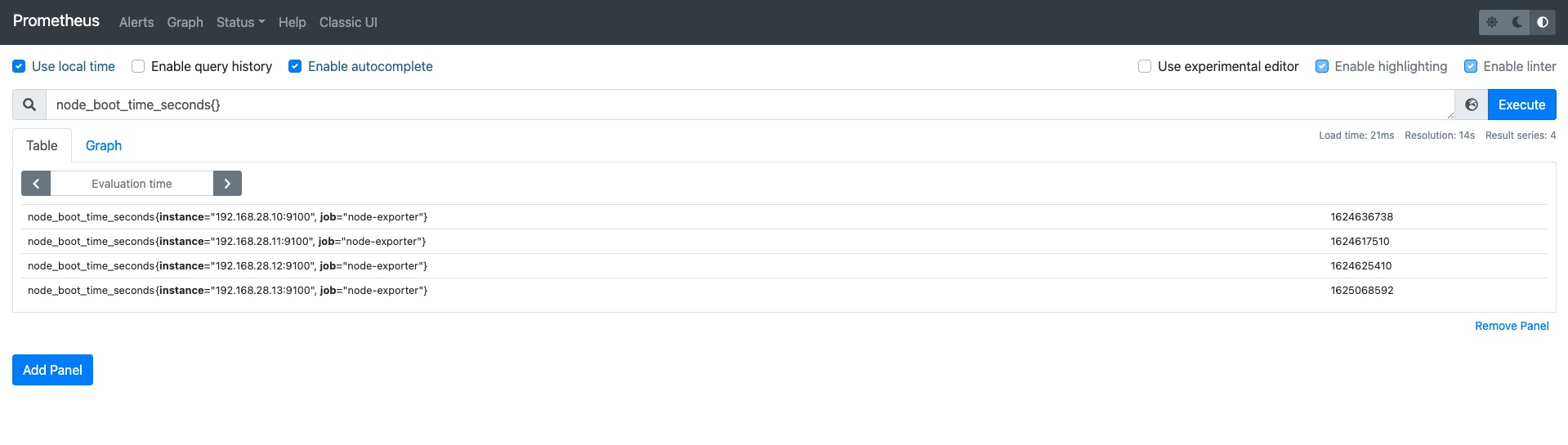
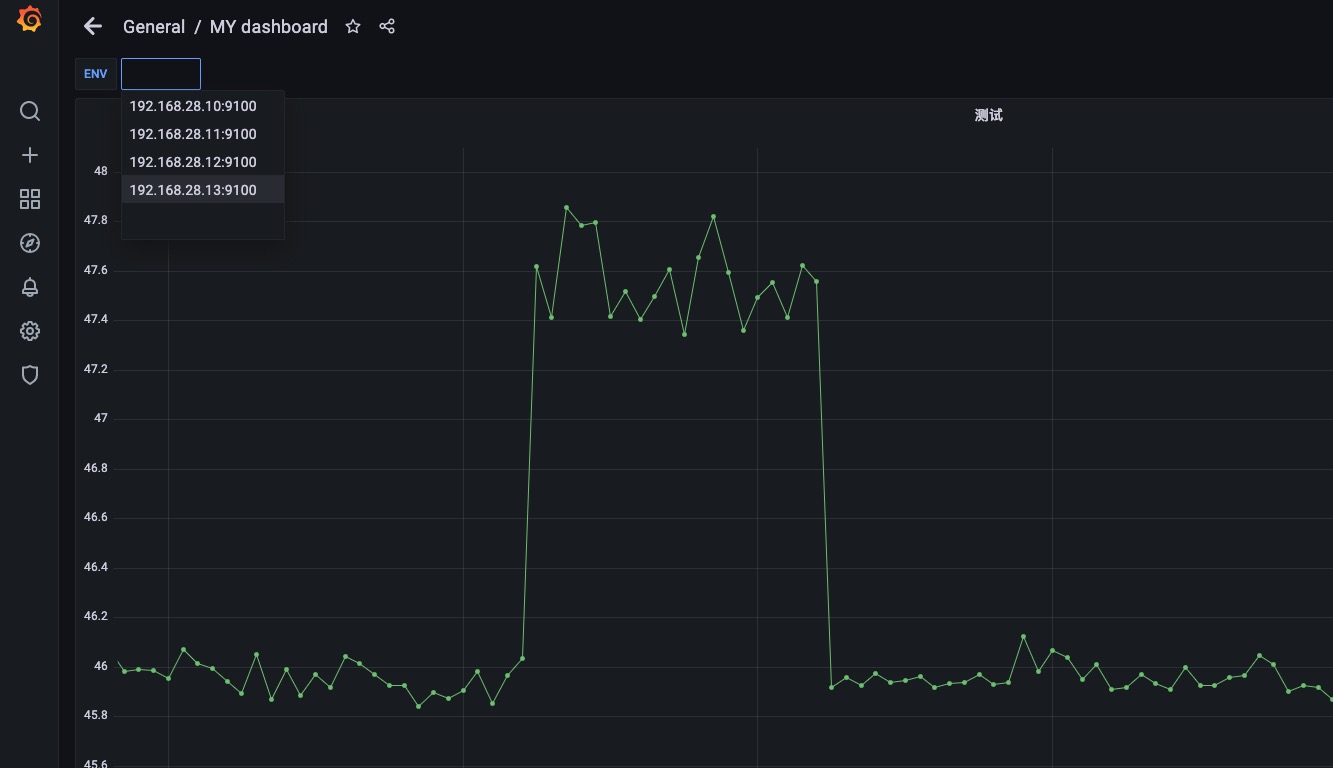
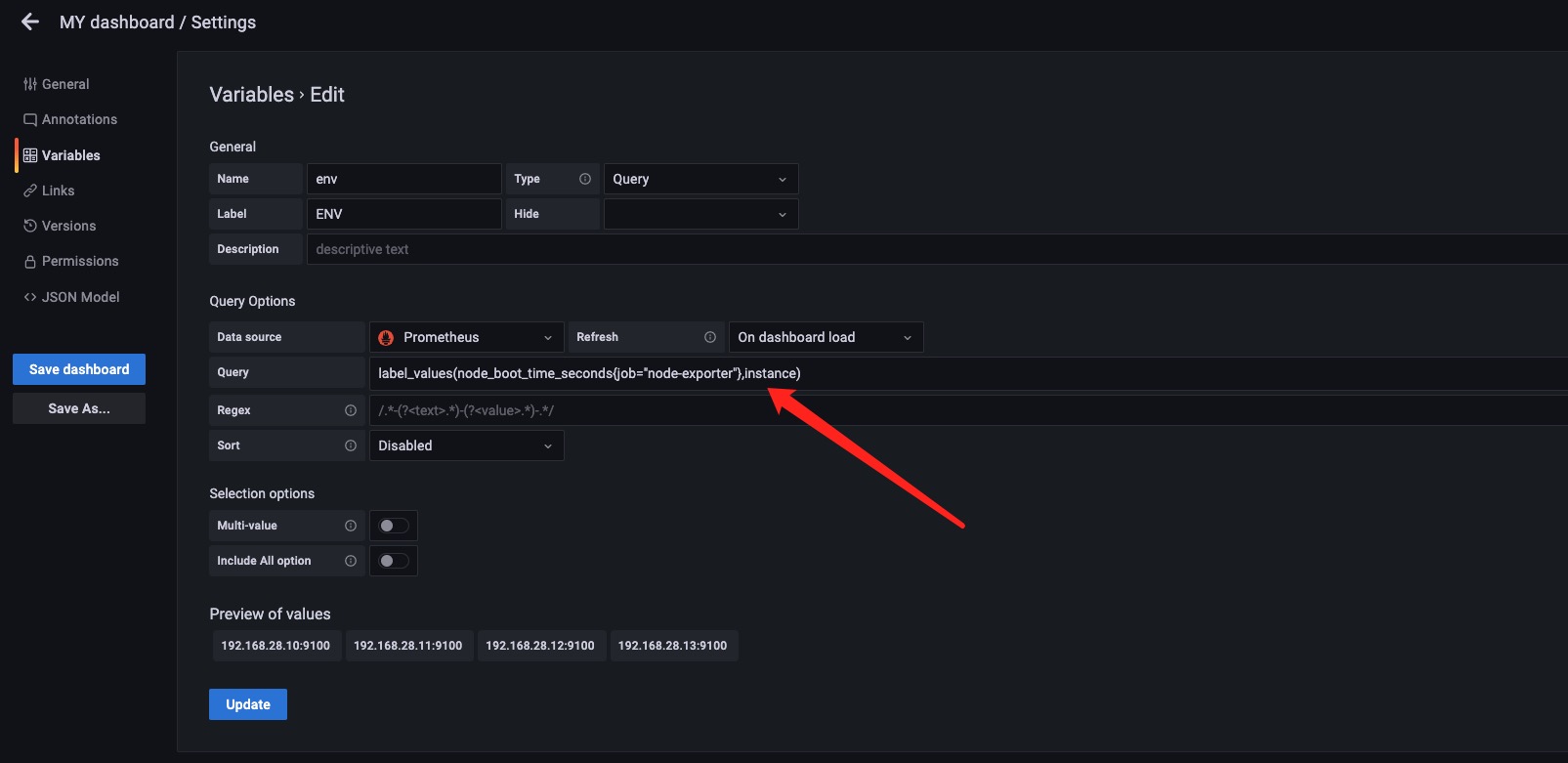
我们也可以设置标签的过滤条件例如上图。label_values(node_boot_time_seconds{job="node-exporter"},instance) 这样就是先过滤出来node_boot_time_seconds这个指标中标签是{job="node-exporter"}的Target然后在取instance的值赋值给env变量。
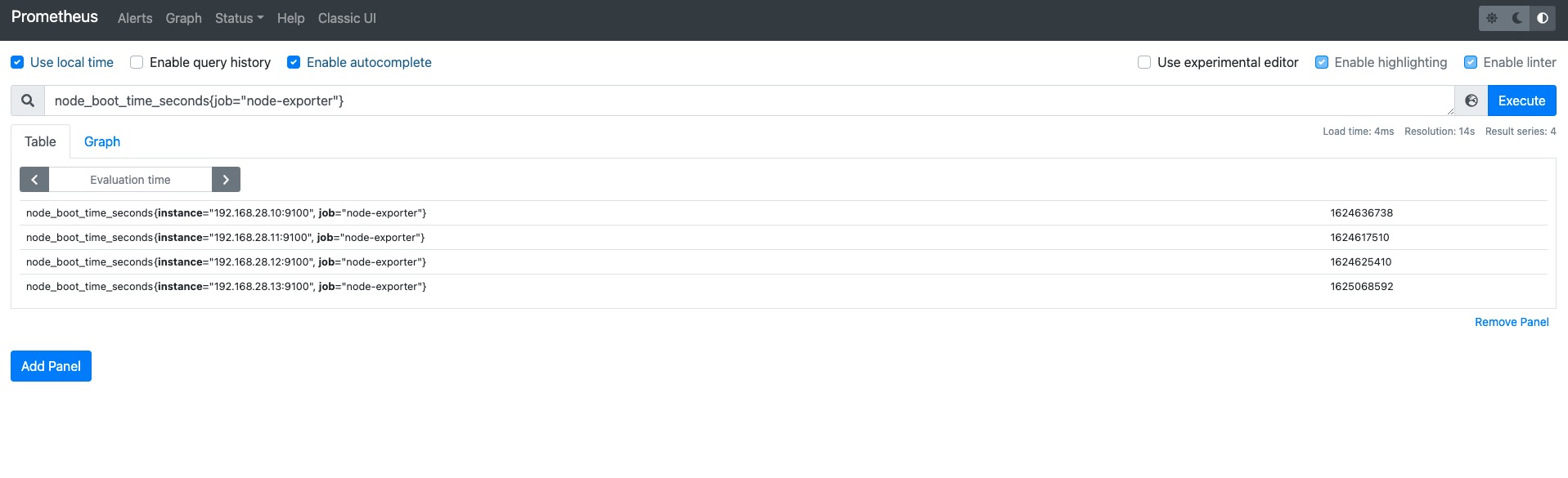
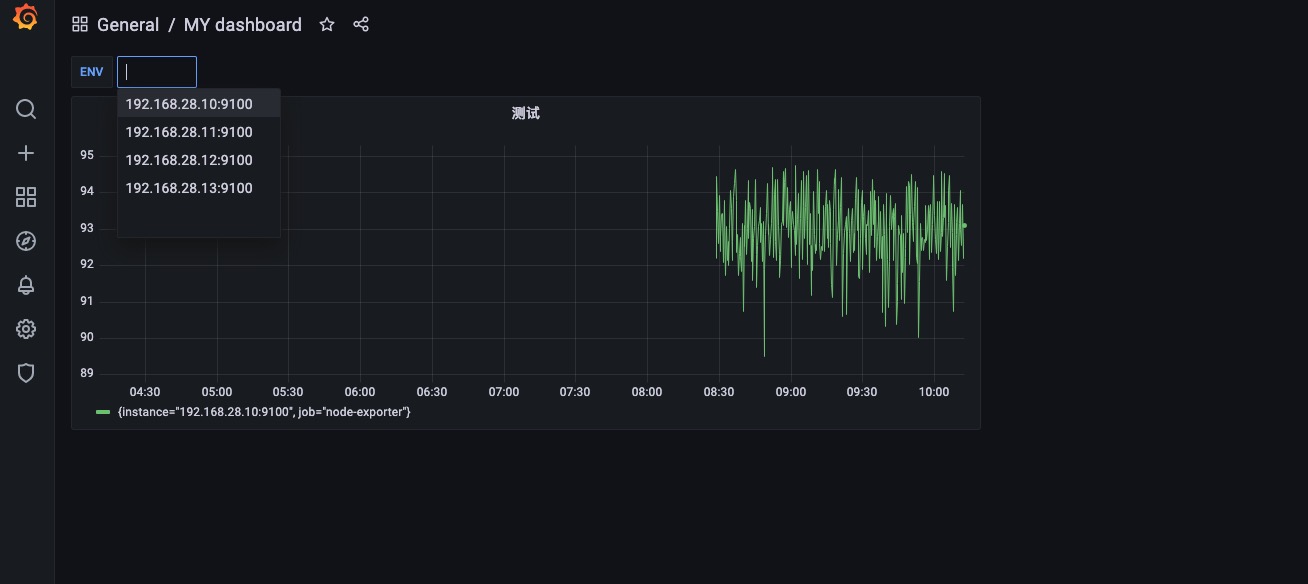
看起来和上面没什么变化,因为4个node_exporter都有job="node-exporter"这个标签,如果某一个主机没有这个标签将在env这里少显示一个。
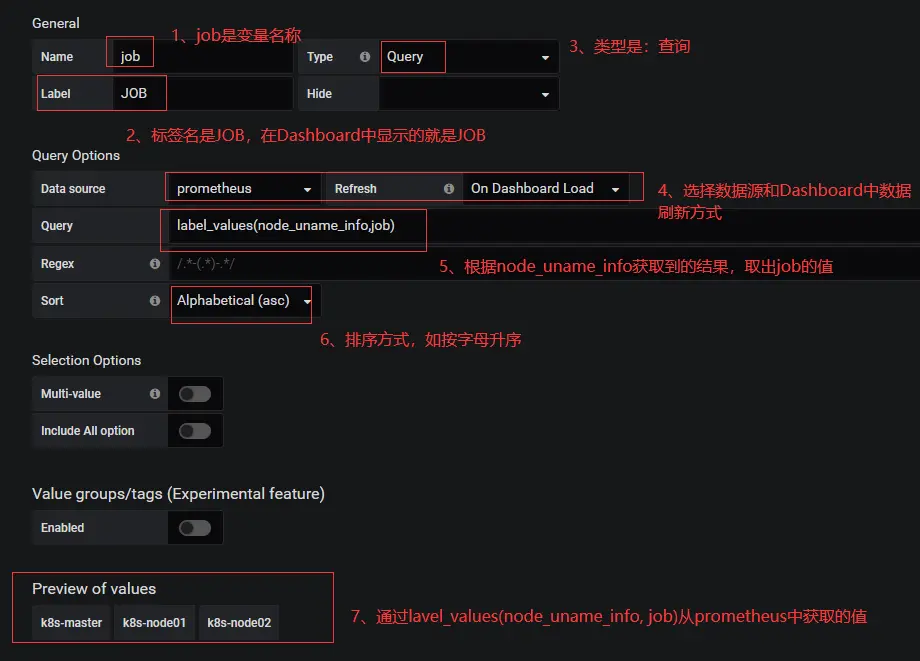
Grafana变量使用
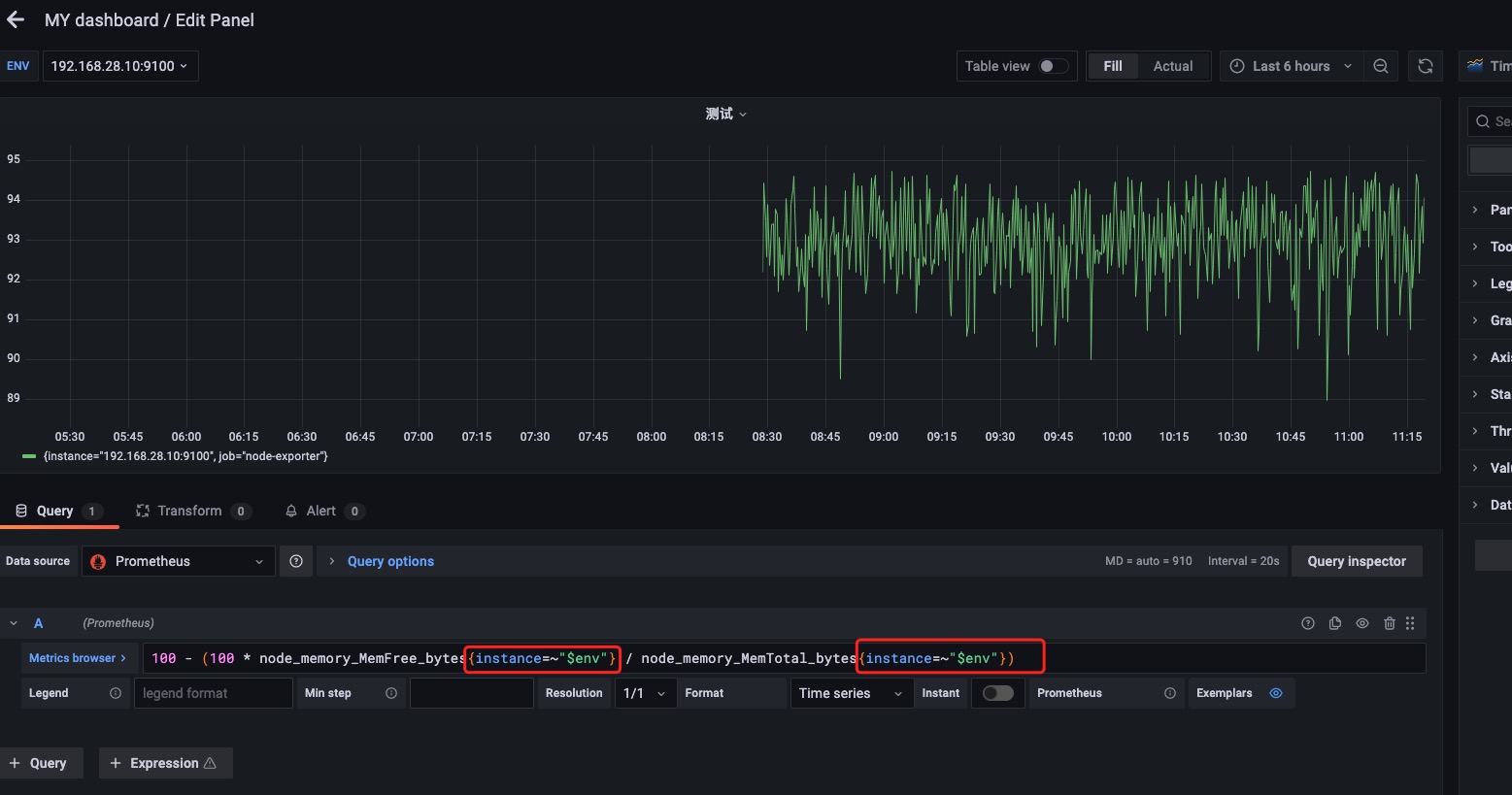
在每个指标名后面加上标签名,其中标签值就是变量名env。
正则表达式使用
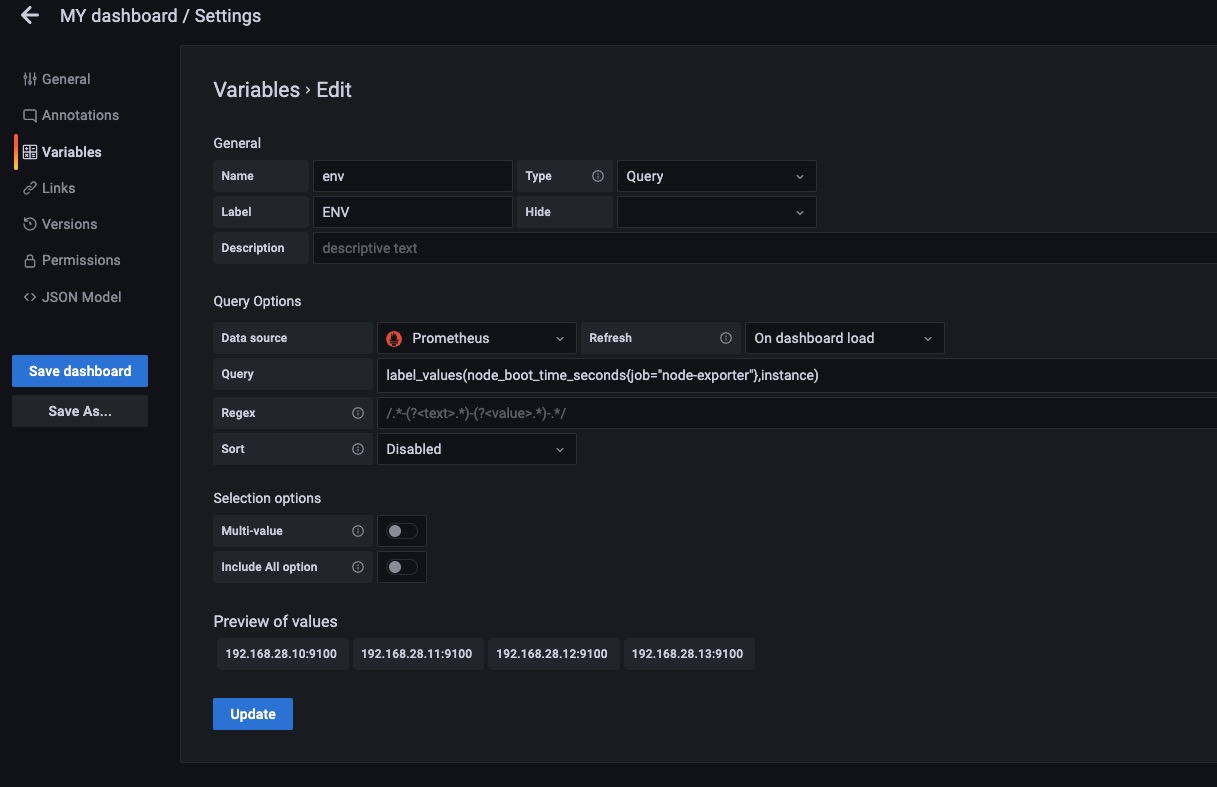
如上图所示我们在没有加正则表达时候的时候我们获取到的instance的结果是IP+Port的形式。
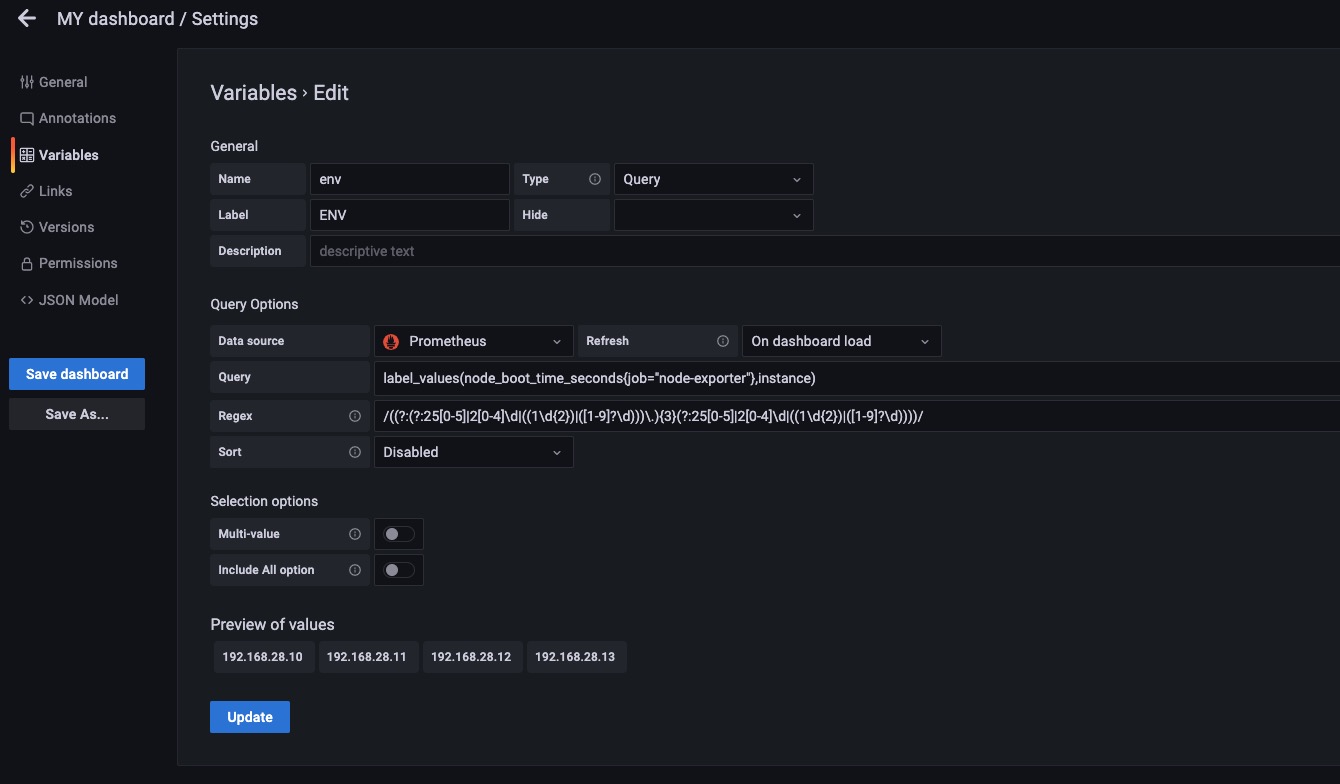
我们加了正则表达式后可以对Query的结果进行二次处理。也就是用正则表达在匹配一次,匹配出我们需要的结果,这次我们去掉了端口。
Grafana刷新时间
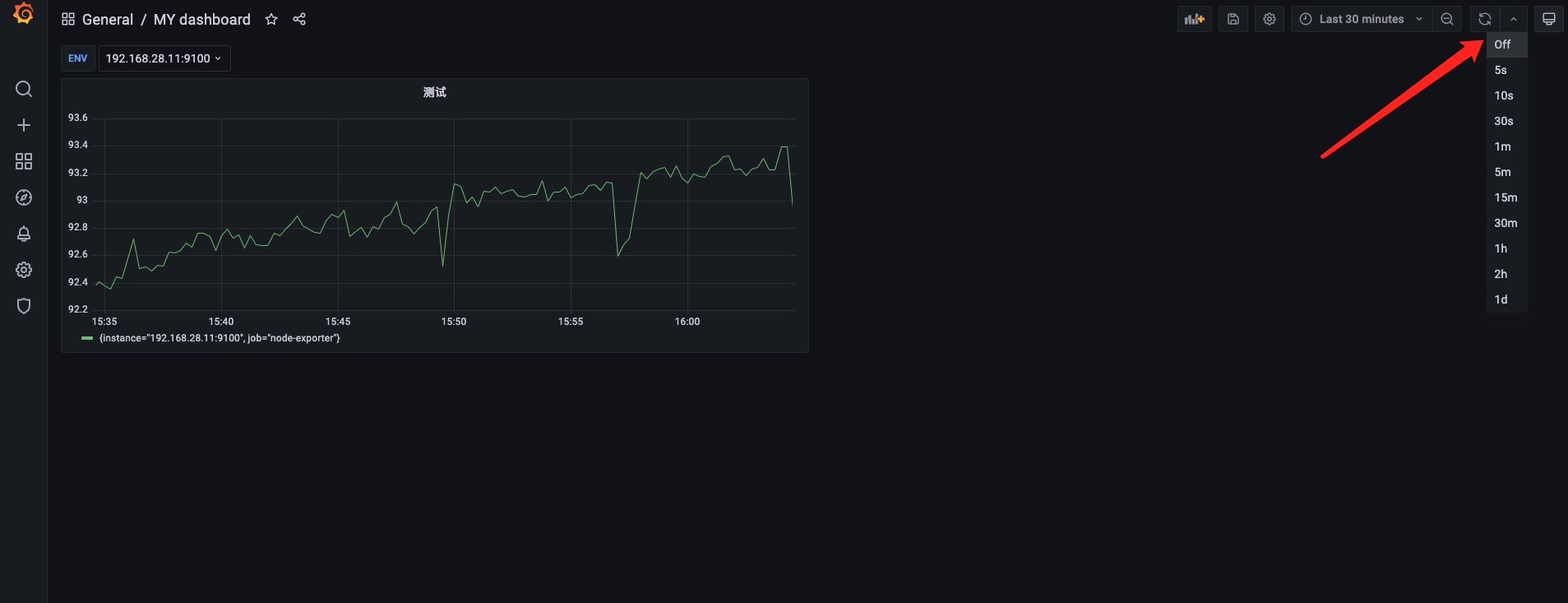
这里可以设置多久刷新一次Dashboard时间,也就是多久执行一次面板后面的PromQL。