前面我们已经学习了 Prometheus 的使用,了解了基本的 PromQL 语句以及结合 Grafana 来进行监控图表展示,通过 AlertManager 来进行报警,这些工具结合起来已经可以帮助我们搭建一套比较完整的监控报警系统了,但是也仅仅局限于测试环境,对于生产环境来说则还有许多需要改进的地方,其中一个非常重要的就是 Prometheus 的高可用。
单台的 Prometheus 存在单点故障的风险,随着监控规模的扩大,Prometheus 产生的数据量也会非常大,性能和存储都会面临问题。毋庸置疑,我们需要一套高可用的 Prometheus 集群。这里我根据我们公司的Prometheus架构来讲一下我们是怎么用的。
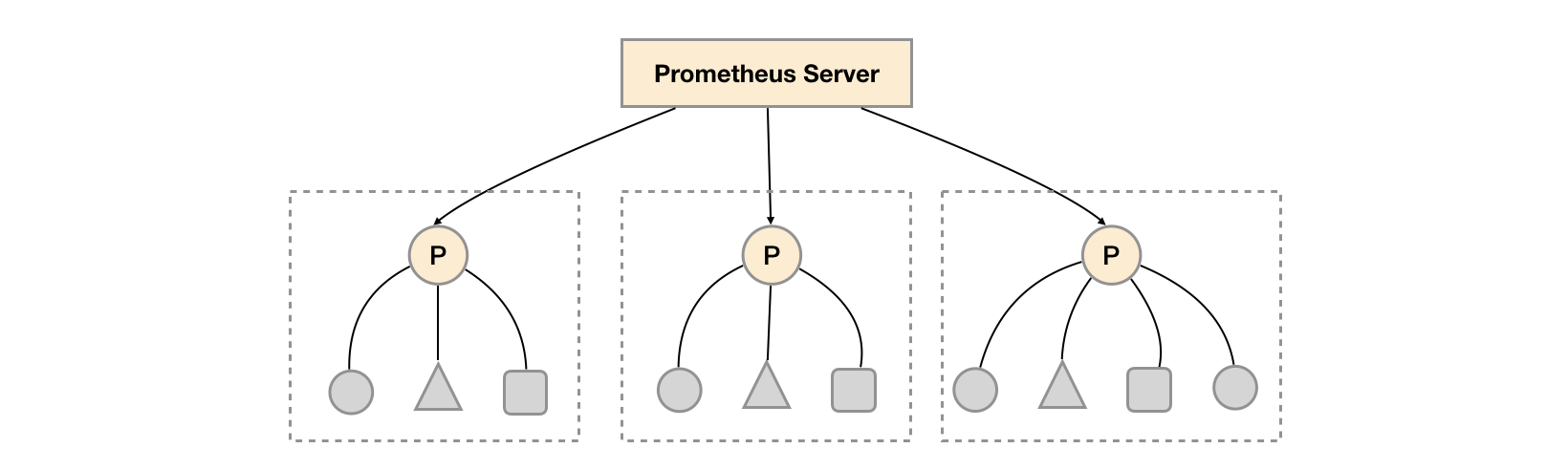
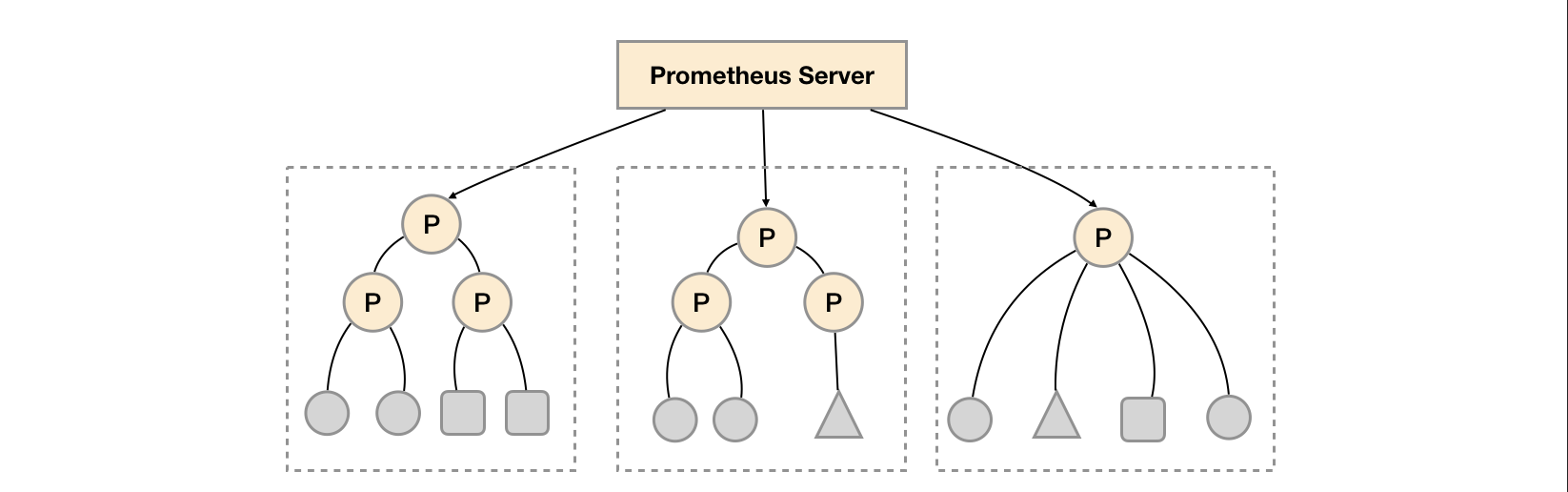
联邦集群 当单个 Promthues 实例无法处理大量的采集任务时,这个时候我们就可以使用基于 Prometheus 联邦集群的方式来将监控任务划分到不同的 Prometheus 实例中去。Prometheus 联邦允许一台 Prometheus Server 从另一台 Prometheus Server 抓取符合特定条件的数据。Prometheus 的联邦有不同的使用方式,分层联邦和跨服务联邦;
分层联邦(Hierarchical federation) 一个联邦设置可能由多个机房 Prometheus Server 和一套全局 Prometheus Server组成。每个机房的Prometheus Server负责收集本区域内的数据,全局 Prometheus 服务器从这些下层 Prometheus Server中收集和汇聚数据,并存储聚合后的数据。这样就提供了一个聚合的全局视角和详细的本地视角。
跨服务联邦(Cross-service federation) 比如说有一个Prometheus Server A用来采集node_exporter的Metrics,而Prometheus Server B则用来采集mysql_exporter的Metrics,最后由全局Prometheus通过联邦的方式来汇总两个Prometheus Server的数据。(可以通过下图中的圆圈和正方形理解)
Prometheus联邦配置 source prometheus不用修改什么,prometheus配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 global : scrape_interval : 60s scrape_timeout : 60s evaluation_interval : 120s alerting : alertmanagers : - static_configs: - targets: rule_files : scrape_configs : - job_name: 'node-exporter' consul_sd_configs : - server: '127.0.0.1:8500' datacenter : 'lzw' services : []
中心Prometheus从下层Prometheus中拉取数据配置如下(match[]参数是必须配置项):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 global : scrape_interval : 15s evaluation_interval : 30s alerting : alertmanagers : - static_configs: - targets: - 10.15.1.29:9093 rule_files : - "rules/recording_rules.yaml" - "rules/alerts.yml" scrape_configs : - job_name: grafana static_configs : - targets: - '10.15.1.29:3000' - job_name: 'cluster-a' scrape_interval : 60s scrape_timeout : 60s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~".+"}' static_configs : - targets: - '10.15.1.30:9090' - job_name: 'cluster-b' scrape_interval : 60s scrape_timeout : 60s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~".+"}' static_configs : - targets: - '10.15.1.31:9090'
主机
角色
10.15.1.29
中心Prometheus
10.15.1.30
Prometheus Server
10.15.1.31
Prometheus Server
10.15.1.32
node_exporter被10.15.1.30采集
10.15.1.46
node_exporter被10.15.1.31采集
实际生产中用例 在生产中不建议使用'{job=~".+"}' 匹配拉取所有数据,由于数据量大,可能会导致中心Prometheus拉取数据失败。所以在生产中最好是分组拉取。根据分中心不同的job或namespaces标签做区分。这里还需要注意scrape_interval 和 scrape_timeout 两个参数。如果分中心promethues设置的时间为30s,中心Prometheus可以设置为35s或40s时间大于分中心的抓取时间,但是不能大于他的倍数例如60s。不然绘图偶尔会出现断断续续的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 - job_name: 'cluster-a' scrape_interval : 45s scrape_timeout : 45s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~".+"}' static_configs : - targets: - '172.16.60.244:9090' - job_name: 'kube-apiserver' scrape_interval : 45s scrape_timeout : 45s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~"kube-apiserver"}' static_configs : - targets: - '172.16.50.31:30080' - job_name: 'etcd' scrape_interval : 45s scrape_timeout : 45s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~"etcd-k8s"}' static_configs : - targets: - '172.16.50.31:30080' - job_name: 'ingress-nginx-endpoints' scrape_interval : 45s scrape_timeout : 45s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~"ingress-nginx-endpoints"}' static_configs : - targets: - '172.16.50.31:30080' - job_name: 'kube-state-metrics' scrape_interval : 45s scrape_timeout : 45s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~"kube-state-metrics"}' static_configs : - targets: - '172.16.50.31:30080' - job_name: 'kubernetes' scrape_interval : 45s scrape_timeout : 45s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~"kubernetes.*"}' static_configs : - targets: - '172.16.50.31:30080' - job_name: 'kubelet' scrape_interval : 45s scrape_timeout : 45s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job=~"kubelet"}' static_configs : - targets: - '172.16.50.31:30080' - job_name: 'kube-system' scrape_interval : 35s scrape_timeout : 35s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{namespace="kube-system",job=~"metrics-server|kube-dns"}' #以名称空间做抓取过滤 static_configs : - targets: - '172.16.50.31:30080' - job_name: 'pmsp' scrape_interval : 35s scrape_timeout : 35s honor_labels : true metrics_path : '/federate' params : 'match[]' : - '{job="svc-staffsit-java"}' static_configs : - targets: - '172.16.50.31:30080'
外部存储VictoriaMetrics VictoriaMetrics是一个快速高效且可扩展的监控解决方案和时序数据库,可以作为Prometheus的长期远端存储。这里我们架构使用Prometheus联邦模式加VictoriaMetrics作为外部存储,将中心Prometheus数据使用remote_write的方式写入到VictoriaMetrics中,Prometheus将传入数据写入本地存储并并行复制到远程存储。这意味着即使远程存储不可用,数据在本地存储中仍可用 --storage.tsdb.retention.time 持续时间。实际上VictoriaMetrics自己也有一套监控方案可以用来替代现有的Prometheus,这里我仅使用VictoriaMetrics的存储功能。
安装VictoriaMetrics VictoriaMetrics分两个版本一个是单机版一个是集群版,我们使用单机版即可。
1 2 3 4 5 6 # 下载victoriametrics @devops010015001029 shallwe]# wget https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.63.0/victoria-metrics-amd64-v1.63.0.tar.gz @devops010015001029 shallwe]# tar -zxv -f victoria-metrics-amd64-v1.63.0.tar.gz @devops010015001029 shallwe]# mkdir -pv /usr/local/victoriametrics/{bin,conf,data} @devops010015001029 shallwe]# mv victoria-metrics-prod /usr/local/victoriametrics/bin/ @devops010015001029 shallwe]# mkdir -pv /run/victoriametrics
配置victoriametrics启动参数 注意:下面部分参数需要修改,根据自己的主机情况修改,以下参数并不适用所有主机。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@devops010015001029 shallwe] VICTORIAMETRICS_OPT =-http.connTimeout=5 m \-maxConcurrentInserts =20000 \-maxInsertRequestSize =100 MB \-maxLabelsPerTimeseries =200 \-insert.maxQueueDuration =5 m \-dedup.minScrapeInterval =60 s \-bigMergeConcurrency =20 \-retentionPeriod =180 d \-search.maxQueryDuration =10 m \-search.maxQueryLen =30 MB \-search.maxQueueDuration =60 s \-search.maxConcurrentRequests =32 \-storageDataPath =/usr/local/victoriametrics/data \
设置开机启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@devops010015001029 shallwe] [Unit] Description =victoriametricsAfter =network.target[Service] Type =simpleLimitNOFILE =1024000 LimitNPROC =1024000 LimitCORE =infinityLimitMEMLOCK =infinityEnvironmentFile =-/usr/local/victoriametrics/conf/victoriametricsPIDFile =/run/victoriametrics/victoriametrics.pidExecStart =/usr/local/victoriametrics/bin/victoria-metrics-prod $VICTORIAMETRICS_OPT ExecStop =/bin/kill -s SIGTERM $MAINPID Restart =on -failureRestartSec =1 KillMode =process[Install] WantedBy =multi-user.target[root@devops010015001029 shallwe] [root@devops010015001029 shallwe] [root@devops010015001029 shallwe]
Prometheus数据写入victoriametrics 将以下行添加到 Prometheus 配置文件(prometheus.yml)
1 2 3 4 5 6 7 8 9 10 11 remote_write: remote_timeout: 30 s queue_config: capacity: 20000 max_shards: 50 min_shards: 1 max_samples_per_send: 10000 batch_send_deadline: 60 s min_backoff: 30 ms max_backoff: 100 ms
prometheus的remote write功能 prometheus配置了remote write的目标地址后,它会从WAL读取数据,然后把采样数据写入各分片的内存队列,最后发起向远程目标地址的请求。
数据流的逻辑大致如下:
1 2 3 |--> queue (shard_1) -->(shard_...) -->(shard_n) -->
需要注意的是:WAL是每两小时压缩一次,如果远程写入的目标地址挂了超过两个小时,就会导致这段时间没被发送的数据丢失。如果远程写入的目标地址无响应时间较短(两小时以内),prometheus是会重试的,这种情况不会造成数据丢失。
当一个分片的队列被塞满时,promtheus将阻塞继续从WAL读取数据到任意分片。
在操作过程中,prometheus根据以下条件来持续计算要是用的最佳的分片数:
摄入样本的速率(incoming sample rate)
还未发送的样本数量(number of outstanding samples not sent)
发送每个样本的时间(time taken to send each sample)
内存的使用 当开启remote write功能后,prometheus内存的消耗是会上涨的。大部分反馈会上涨约25%的内存消耗,但实际数据取决于数据的分片。
对于WAL中的每一个series,远程写功能会缓存一个series ID到标签值的映射,这会导致内存消耗的大量增加。
除此之外,每个分片和其队列也增加了内存的使用。分片内存与 number of shards * (capacity + max_samples_per_send)成正比。默认的capacity和max_samples_per_send将限制每个分片的内存使用小于100KB。
相关参数 remote write的相关参数在queue_config配置块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <int> | default = 500 ]<int> | default = 1000 ]<int> | default = 1 ]<int> | default = 100 ]<duration> | default = 5 s ]<duration> | default = 30 ms ]<duration> | default = 100 ms ]
capacity
通过设大capacity可以避免分片的阻塞,但是会导致过多的内存消耗,以及resharing时清空队列所需要的时间。
max_shards
min_shards
max_samples_per_send
batch_send_deadline
min_backoff
max_backoff
Prometheus 设置开机启动 systemd服务:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@devops010015001029 conf] [Unit] Description =prometheusWants =network-on line.target[Service] LimitNOFILE =1024000 LimitNPROC =1024000 LimitCORE =infinityLimitMEMLOCK =infinityEnvironmentFile =-/usr/local/prometheus/conf/prometheusExecStart =/usr/local/prometheus/prometheus $PROMETHEUS_OPTS Restart =on -failureKillMode =process[Install] WantedBy =multi-user.target
参数配置:
1 2 3 4 5 6 7 8 9 [root@devops010015001029 conf]# vim /usr/local/prometheus/conf/prometheusPROMETHEUS_OPTS =--config.file=/usr/local/prometheus/prometheus.yml \listen-address =:9090 \path =/data/prometheus \time =2d \min-block-duration =2h \max-block-duration =2h \
可配置的参数(可参考):
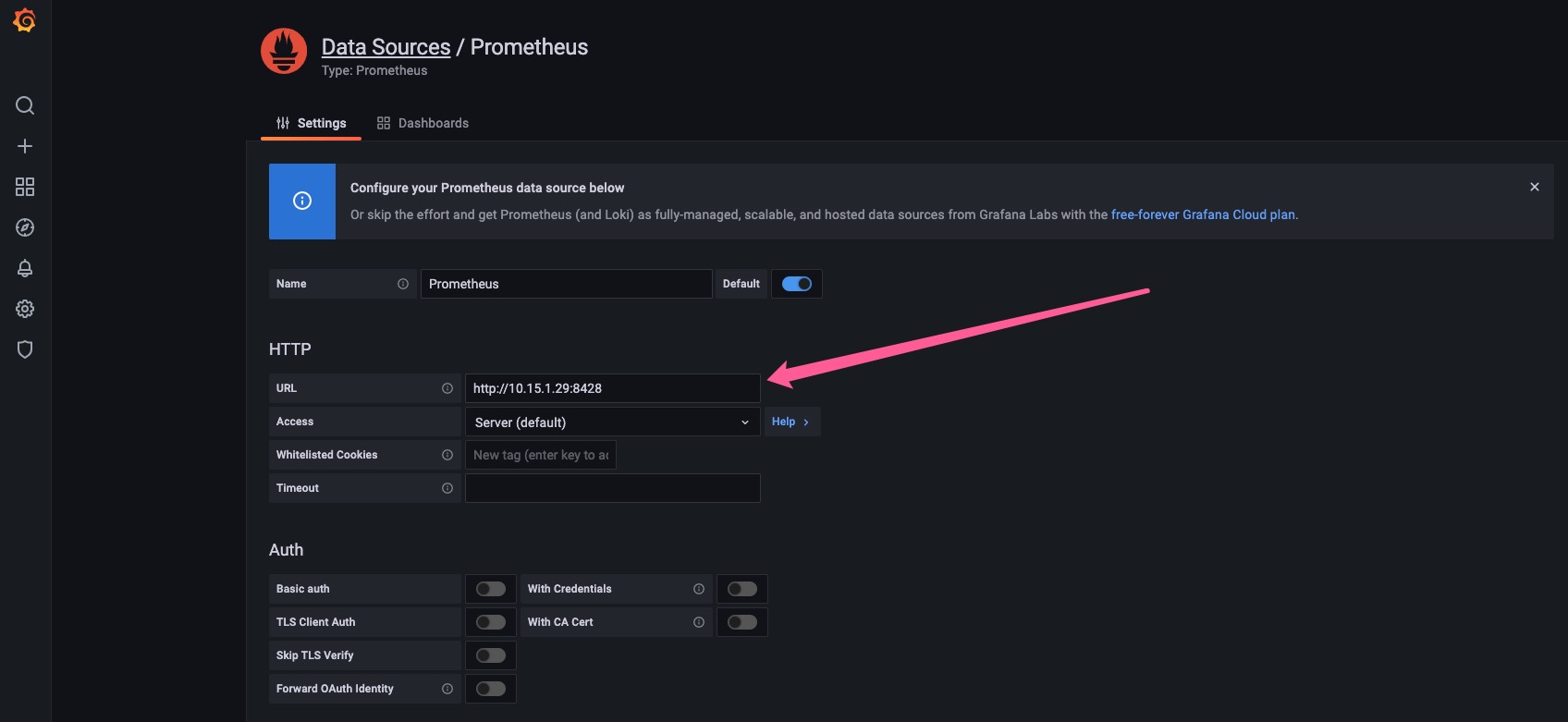
Grafana设置 使用以下 URL 在 Grafana 中创建 Prometheus 数据源:
1 http:// <victoriametrics-addr>:8428
替换<victoriametrics-addr>为 VictoriaMetrics 的主机名或 IP 地址。
Prometheus本地存储 Prometheus内置了TSDB时序数据库,内置的时序数据给Prometheus带来了简单高效的使用体验,Prometheus2.0 版本引入了全新的V3存储引擎,每秒可处理数百万个样本,可以在单节点的情况下满足大部分用户的监控需求。
Prometheus TSDB数据存储格式概览
以每2小时为一个时间窗口,并存储为一个单独的block;
block会压缩、合并历史数据块,随着压缩合并,其block数量会减少;
block的大小并不固定,但最小会保存两个小时的数据;(因为有些时候你添加了样本或者减少了样本数就会导致block大小不一样)
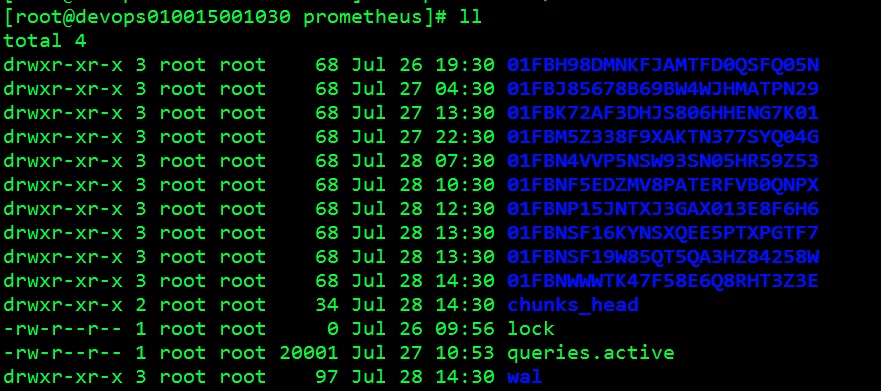
下图为block文件
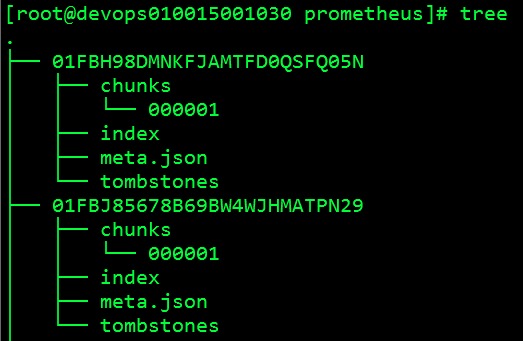
TSDB Block 每个block都有单独的目录,里面包含该时间窗口内所有的chunk、index、 tombstones、meta.json
chunks: 用于保存时序数据,每个chunk的大小为512MB,超出该大小时则截断并创建为另一个Chunk;各Chunk以数字编号;
index: 索引文件,它是Prometheus TSDB实现高效查询的基础;我们甚至可以通过Metrics Name和Labels查找时间序列数据在chunk文件中的位置;索引文件会将指标名称和标签索 引到样本数据的时间序列中;
tombstones: 用于对数据进行软删除,即“标记删除”,以降低删除操作的成本;删除的记录并保存于tombstones文件中,而读取时间序列上的数据时,会基于tombstones进行过滤已经删除的部分;
meta.json: block的元数据信息,这些元数据信息是block的合并、删除等操作的基础依赖;
下图为Block文件中的文件
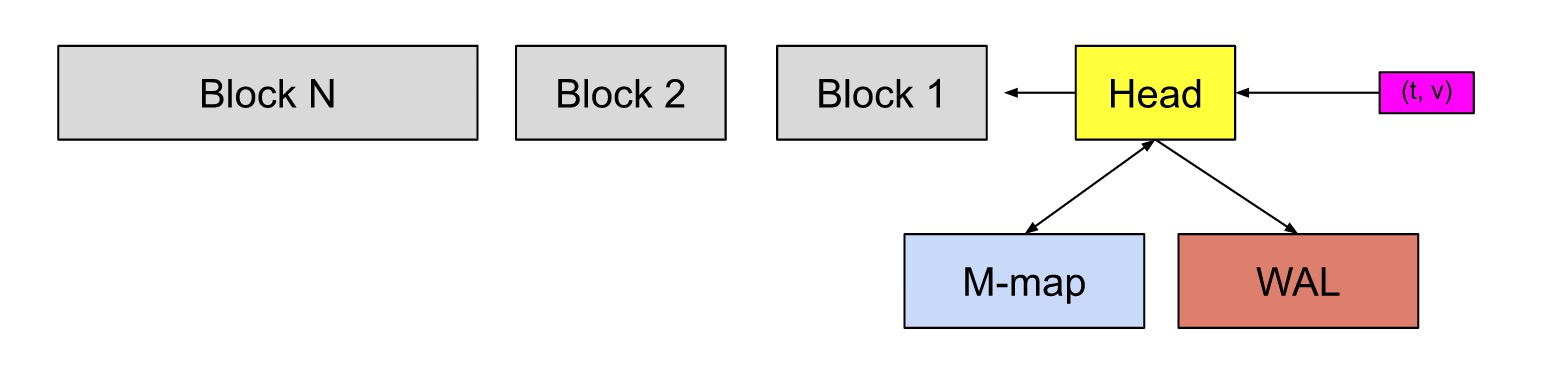
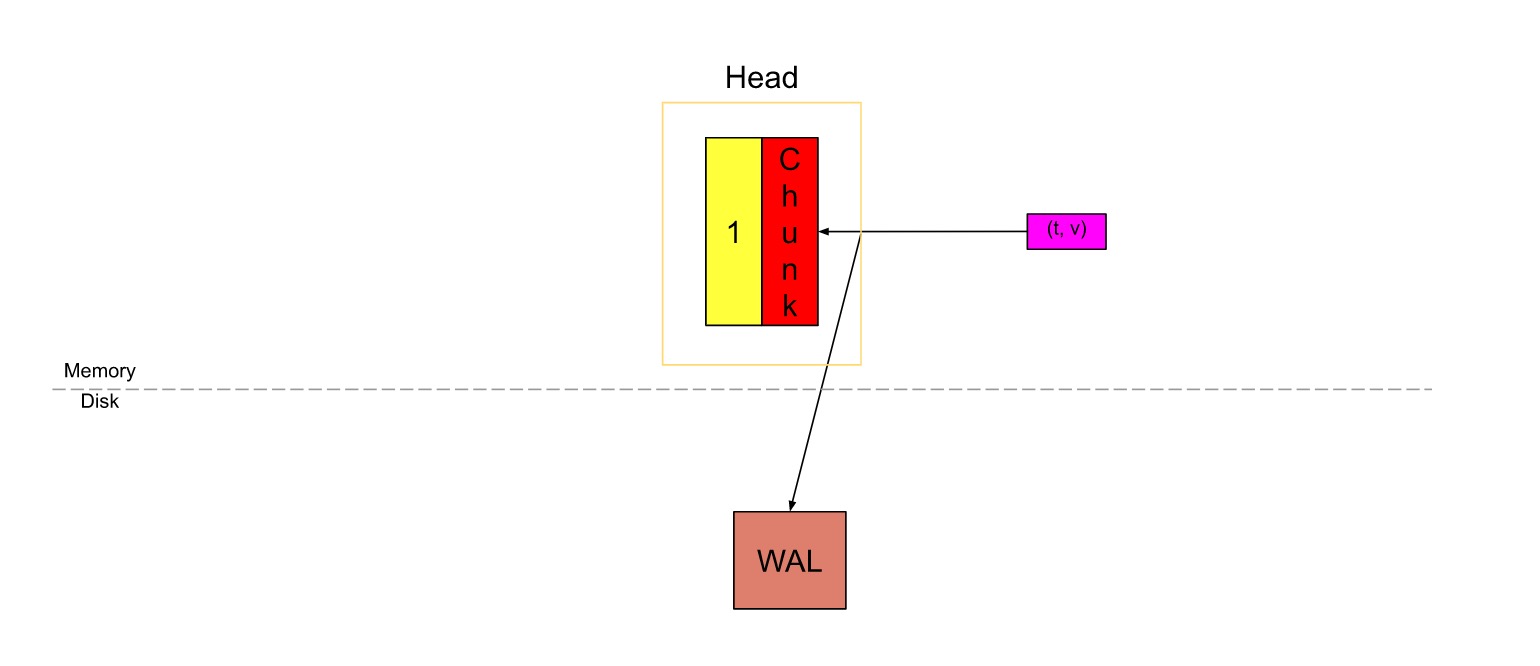
WAL
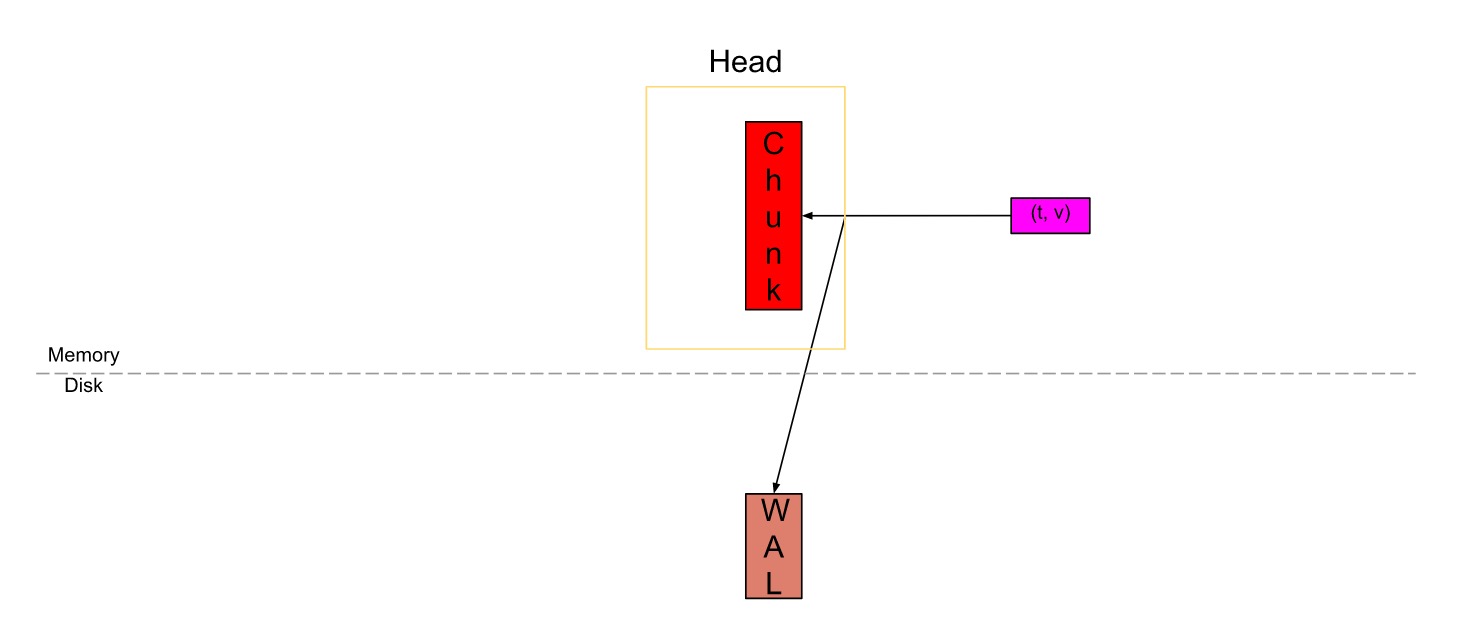
在上图中,Head块是数据库的内存部分,灰色块是磁盘上不可更改的持久块。我们有一个预写日志(WAL)用于持久写入。传入的sample(粉红色的方框)首先进入Head块,并在内存中停留一段时间,然后刷新到磁盘并映射到内存(蓝色的方框)。当这些内存映射的块或内存中的块变旧到一定程度时,它们会作为持久性块被刷新到磁盘。随着它们变旧,将合并更多的块,并在超过保留期限后将其最终删除。
WAL是数据库中发生的事件的顺序日志。在写入/修改/删除数据库中的数据之前,首先将事件记录(附加)到WAL中,然后在数据库中执行必要的操作。
不管出于何种原因,如果机器或程序崩溃,都会在此WAL中记录事件,您可以按照相同的顺序重播这些事件以恢复数据。这对于内存数据库尤其有用,在内存数据库中,如果数据库崩溃,则如果不是WAL,则内存中的所有数据都会丢失。(这里相当于redis 的AOF恢复数据是一个道理他会把文件中的命令一个一个的执行完。以达到恢复到崩溃前)
Prometheus存储配置 配置参数
–storage.tsdb.path: 数据存储路径,WAL日志亦会存储于该目录下,默认为data;
–storage.tsdb.retention.time: 样本数据在存储中保存的时长,超过该时长的数据就会被删除;默认为15d;
–storage.tsdb.retention.size: 每个Block的最大字节数(不包括WAL文件),支持B、KB、 MB、GB、TB、PB和EB,例如512MB等(此参数是实验性的,在未来版本中可能会更改);
–storage.tsdb.wal-compression: 是否启用WAL的压缩机制,2.20及以后的版本中默认即为启用;
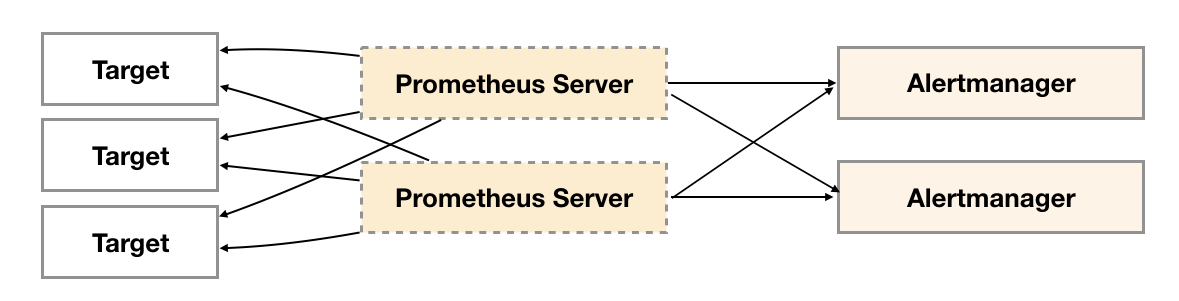
Alertmanager高可用 为了提升Promthues的服务可用性,通常用户会部署两个或者两个以上的Promthus Server。这样解决了Prometheus高可用的问题,但是我们的Alertmanager目前仍然纯在单点故障风险。当Alertmanager单点失效后,告警的后续所有业务全部失效。
如下所示,最直接的方式,就是尝试部署多套Alertmanager。但是由于Alertmanager之间不存在并不了解彼此的存在,因此则会出现告警通知被不同的Alertmanager重复发送多次的问题。
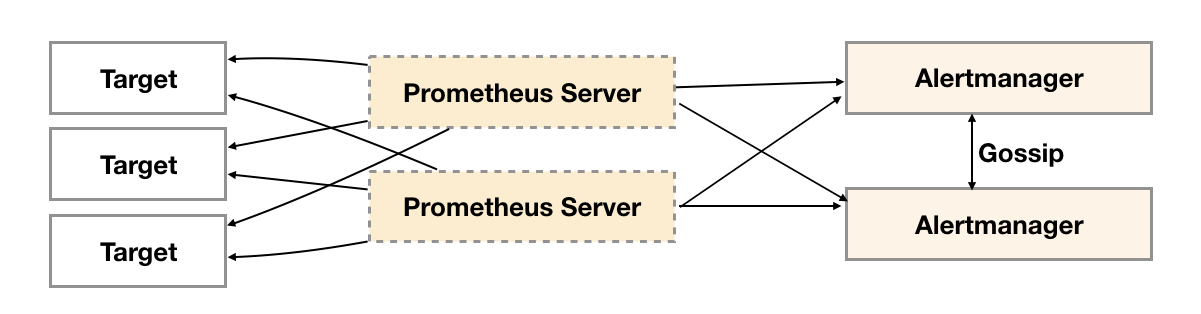
为了解决这一问题,如下所示。Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
创建Alertmanager集群 为了能够让Alertmanager节点之间进行通讯,需要在Alertmanager启动时设置相应的参数。其中主要的参数包括:
1 2 --cluster.listen-address string --cluster.peer value
alertmanager 启动配置文件 实例a1
1 2 3 4 5 6 7 8 [root@devops010015001029 ~] ALERTMANAGER_OPT =--config.file=/usr/local/alertmanager/alertmanager.yml \--storage.path =/usr/local/alertmanager/data \--data.retention =120 h \--web.listen-address =:9093 \--cluster.listen-address ='0.0.0.0:9094' \--log.level =debug \
实例a2
1 2 3 4 5 6 7 8 [root@devops010015001030 ~] ALERTMANAGER_OPT =--config.file=/usr/local/alertmanager/alertmanager.yml \--storage.path =/usr/local/alertmanager/data \--data.retention =120 h \--web.listen-address =:9093 \--cluster.listen-address ='0.0.0.0:9094' \--cluster.peer ='10.15.1.29:9094' \
配置alertmanager 启动脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@devops010015001029 ~] [Unit] Description =alertmanager[Service] LimitNOFILE =1024000 LimitNPROC =1024000 LimitCORE =infinityLimitMEMLOCK =infinityEnvironmentFile =-/usr/local/alertmanager/conf/alertmanagerExecStart =/usr/local/alertmanager/alertmanager $ALERTMANAGER_OPT Restart =on -failureKillMode =process[Install] WantedBy =multi-user.target[root@devops010015001029 conf] [root@devops010015001029 conf] [root@devops010015001029 conf]
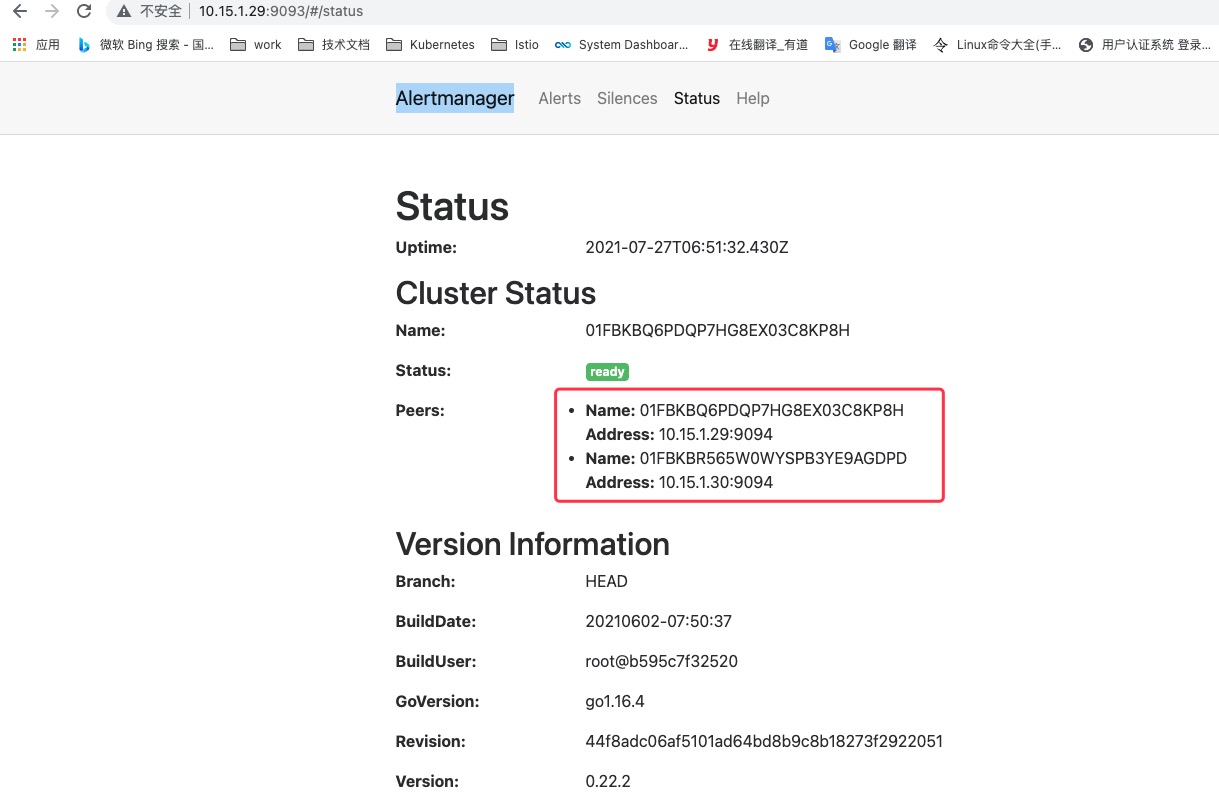
启动完成后访问任意Alertmanager节点http://localhost:9093/#/status可以查看当前Alertmanager集群的状态。
多实例Prometheus与Alertmanager集群 由于Gossip机制的实现,在Promthues和Alertmanager实例之间不要使用任何的负载均衡,需要确保Promthues将告警发送到所有的Alertmanager实例中:
1 2 3 4 5 6 7 alerting : alertmanagers : - static_configs: - targets: - 10.15.1.29:9093 - 10.15.1.30:9093
注意:如果是多个Prometheus Server两边的告警规则一定要一样,不然当某天一台Prometheus宕机以后另外一台没有告警规则导致无法告警。