Docker容器你需要知道的
Docker容器的存活周期
 今天和大家聊聊容器的存活周期,但在聊存活周期以前我们得先了解一下init进程,在Linux操作系统中,当内核初始化完毕之后,会启动一个init进程,这个进程是整个操作系统的第一个用户进程,所以它的进程ID为1,也就是我们常说的PID1进程。在这之后,所有的用户态进程都是该进程的后代进程,由此我们可以看出,整个系统的用户进程,是一棵由init进程作为根的进程树。
 init进程有一个非常厉害的地方,就是SIGKILL信号对它无效。很显然,如果我们将一棵树的树根砍了,那么这棵树就会分解成很多棵子树,这样的最终结果是导致整个操作系统进程杂乱无章,无法管理。所以为了防止用户误操作init进程是无法kill掉的。
 PID 1进程的发展也是一段非常有趣的过程,从最早的sysvinit,到upstart,再到systemd。我们可以用 pstree -p查看PID 1的 进程是谁。
 PID 1的作用是负责清理那些被抛弃的进程(孤儿和僵尸进程)所留下来的痕迹,有效的回收的系统资源,保证系统长时间稳定的运行,可谓是功不可没。在理解了它的重要性之后,我们今天主要探讨一下在容器中的PID 1是怎么回事。
僵尸进程
僵尸进程指的是:进程退出后,到其父进程还未对其调用wait/waitpid之间的这段时间所处的状态。一般来说,这种状态持续的时间很短,所以我们一般很难在系统中捕捉到。但是,一些粗心的程序员可能会忘记调用wait/waitpid,或者由于某种原因未执行该调用等等,那么这个时候就会出现长期驻留的僵尸进程了。如果大量的产生僵尸进程,其进程号就会一直被占用,可能导致系统不能产生新的进程。(子进程挂了,如果父进程不给子进程“收尸”(调用 wait/waitpid),那这个子进程小可怜就变成了僵尸进程。)
孤儿进程
父进程先于子进程退出,那么子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)接管,并由init进程对它完成状态收集(wait/waitpid)工作。
容器中的PID 1
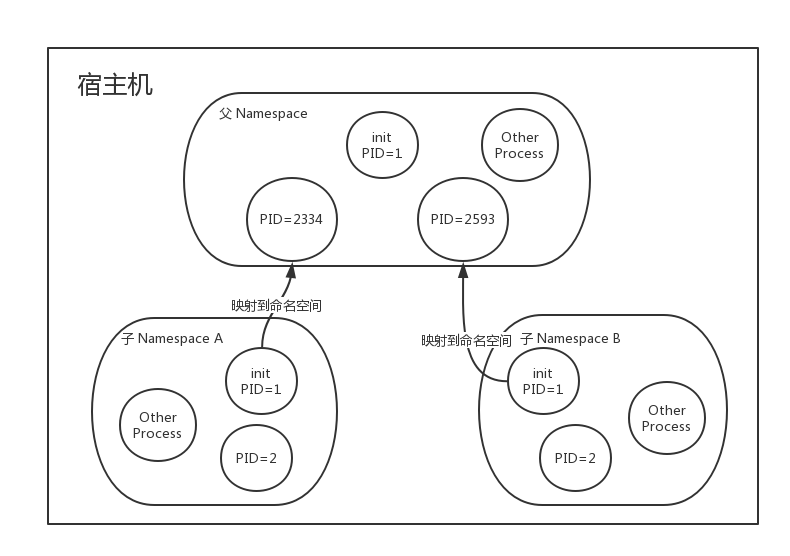
熟悉Docker同学可能知道,容器并不是一个完整的操作系统,它也没有什么内核初始化过程,更没有像init(1)这样的初始化过程。在容器中被标志为PID 1的进程实际上就是一个普普通通的用户进程,也就是我们制作镜像时在Dockerfile中指定的ENTRYPOINT的那个进程。而这个进程在宿主机上有一个普普通通的进程ID,而在容器中之所以变成PID 1,是因为linux内核提供的PID namespaces功能,如果宿主机的所有用户进程构成了一个完整的树型结构,那么PID namespaces实际上就是将这个ENTRYPOINT进程(包括它的后代进程)从这棵大树剪下来,很显然,剪下来的这部分东西本身也是一个树型结构,它完全可以自己长成一棵苍天大树(不断地fork),当然子namespaces里面是看不到整棵树的原貌的,但是父级的namespaces确可以看到完整的子树。
创建一个docker image
1 | |
我们发现pid为1的是一个/bin/sh的进程,容器是单独一个pid namespaces的。通过下图可以更方便理解。由于子namespaces无法看到父级的namespaces,所以容器里第一个进程(也就是cmd)认为自己是pid为1,容器里其余进程都是它的子进程。
在Linux中init进程是不处理SIGKILL信号的,这可以防止init进程被误杀掉,即使是superuser。所以 kill -9 init 不会kill掉init进程。但是容器的进程是在容器的ns里是init级别,我们可以在宿主机上杀掉它
1 | |
1 | |
docker run 后面镜像后面的command和arg会覆盖掉镜像的CMD。上面我那个例子覆盖掉centos镜像默认的CMD bash。我们可以看到ls的容器直接退出了,但是sleep 10的容器运行了10秒后就退出了。以上也说明了容器不是虚拟机,容器是个隔离的进程
这说明了容器的存活是容器里pid为1的进程运行时长决定的。所以nginx的官方镜像里就是用的exec格式让nginx充当pid为1的角色
1 | |
pid 为1 真的好吗
第一种情况实际上php和java的容器在长期运行后经常会频繁oom,主要是代码里涉及到fork等原因(fork程序子进程)。传统Linux上,pid为1的角色承担了孤儿和僵尸进程的回收,但是目前我们的业务进程都是pid为1的角色,没有处理掉孤儿进程,这里我们主进程用bash模仿个僵尸进程看看会不会被回收。
起一个容器exec运行sleep
1 | |
再开一个终端操作按照如下图操作
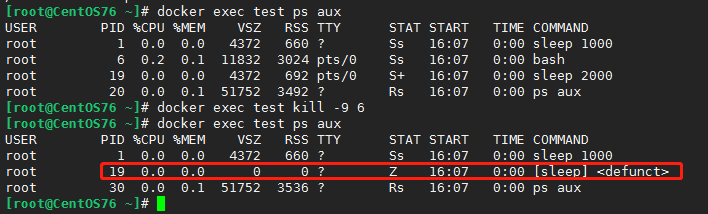
得到一个僵尸进程。解决这个的办法就是pid为1的跑一个支持信号转发且支持回收孤儿僵尸进程的进程就行了,为此有人开发出了tini项目,感兴趣可以github上搜下下,现在tini已经内置在docker里了。
使用tini可以在docker run的时候添加选项–init即可,底层我猜测是复制docker-init到容器的/dev/init路径里然后启动entrypoint cmd,大家可以在run的时候测试下上面的步骤会发现根本不会有僵尸进程遗留。
这里不多说,如果是想默认使用tini可以把tini构建到镜像里(例如k8s目前不支持docker run 的--init,所以需要把tini做到镜像里),参照jenkins官方镜像dockerfile和tini的github地址文档 https://github.com/krallin/tini
如果是基于alpine,tini是依赖glibc的可能还会command not found,可以尝试它的静态版本
1 | |
类似tini的还有dumb-init,例如后续的k8s的ingress nginx镜像就是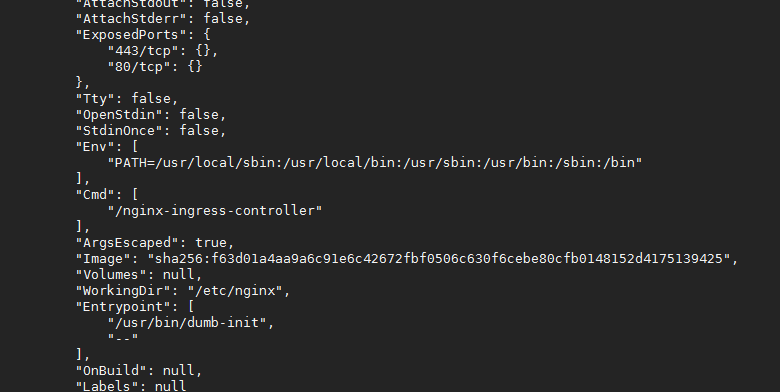
JDK无法识别cgroup限制
首先Docker容器本质是宿主机上的一个进程,它与宿主机共享一个/proc目录,也就是说我们在容器内看到的/proc/meminfo,/proc/cpuinfo与直接在宿主机上看到的一致。
如下:
1 | |
jvm也是读取/proc目录,会导致无法识别cgroup限制。默认情况下,JVM的Max Heap Size是系统内存的1/4,假如我们系统是8G,那么JVM将的默认Heap≈2G。
Docker通过CGroups完成的是对内存的限制,而/proc目录是已只读形式挂载到容器中的,由于默认情况下Java压根就看不见CGroups的限制的内存大小,而默认使用/proc/meminfo中的信息作为内存信息进行启动,这种不兼容情况会导致,如果容器分配的内存小于JVM的内存,JVM进程申请超过限制的内存会被docker认为oom杀掉。
测试用例(OPENJDK)
在JDK8u212版本之前,JVM在容器里面识别到的是宿主机的内存。如果没有手动调整堆大小的话JVM默认会使用1/4的宿主机内存。这样会远远大于容器规格限制的内存,导致内存爆了之后容器自动重启。这里我用我们生产用的openjdk8做演示,jdk8也是一个长期维护版本。测试机器为8G内存,给容器限制内存为4G,看JDK默认参数下的最大堆为多少。
测试命令为如下: (jdk包含jre)
1 | |
OpenJDK8新版本(正确的识别容器限制,910.50M)安全
1
2
3
4
5
6
7
8
9[root@k8s-n1 shallwe]# docker run -m 4GB --rm openjdk:8-jdk java -XshowSettings:vm -version
VM settings:
Max. Heap Size (Estimated): 910.50M
Ergonomics Machine Class: server
Using VM: OpenJDK 64-Bit Server VM
openjdk version "1.8.0_265"
OpenJDK Runtime Environment (build 1.8.0_265-b01)
OpenJDK 64-Bit Server VM (build 25.265-b01, mixed mode)OpenJDK8老版本(并没有识别容器限制,1.69G) 危险
1
2
3
4
5
6
7
8
9[root@k8s-n1 shallwe]# docker run -m 4GB --rm openjdk:8u181 java -XshowSettings:vm -version
VM settings:
Max. Heap Size (Estimated): 1.69G
Ergonomics Machine Class: server
Using VM: OpenJDK 64-Bit Server VM
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-2~deb9u1-b13)
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
结论
OpenJDK8老版本无法识别容器限制,至于其他版本或者其他发行版的jdk我就不测了,我们在选jdk的时候可以选OpenJDK8或adoptopenjdk。如果你想要的是,不显示的指定-Xmx,让Java进程自动的发现容器限制,那么请选择JDK8u212之后的版本。如果你想要的是手动挡的体验,更加进一步的利用内存资源,那么你可能需要回到手动配置-Xmx时代,那么你选什么版本都无所谓了。
CMD和ENTRYPOINT指令的作用和区别
首先先来说说他们两的相同点,他们都有两种写法EXEC和SHELL写法。前者是exec格式也是推荐格式,后者是SHELL格式。当一个dockerfile文件中有多个CMD和ENTRYPOINT时只有最后一个生效。
1 | |
1 | |
以SHELL风格示例
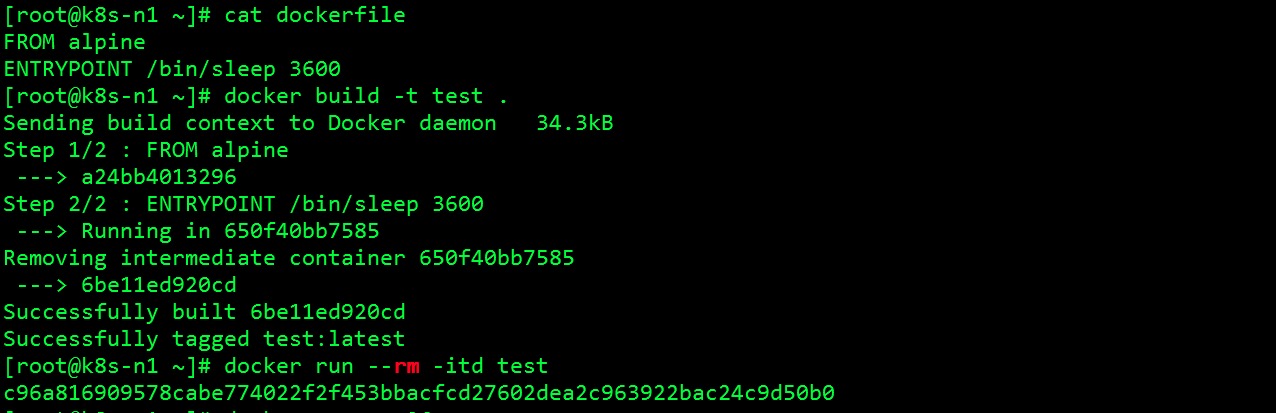
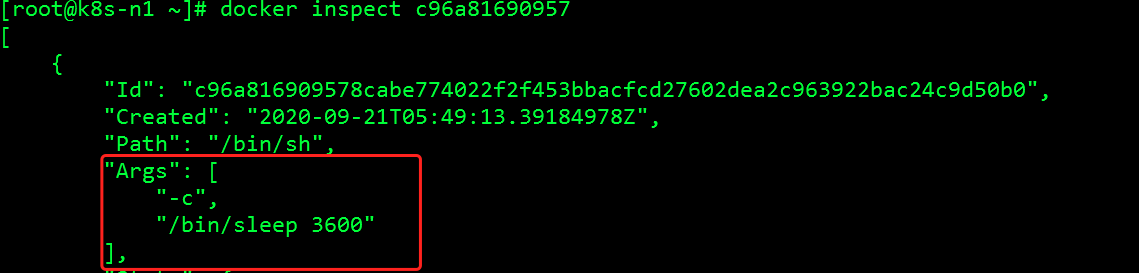

此时的可执行体/bin/sleep是由/bin/sh启动的,我们发现pid为1的是一个/bin/sh的进程。当我们用docker stop命令来停掉容器的时候会先向容器中PID为1的进程发送系统信号SIGTERM,docker默认会允许容器中的应用程序有10秒的时间用以终止运行。如果等待时间超过10秒会继续发送SIGKILL的系统信号强行kill掉进程。一般业务进程都是pid为1,所有官方的进程都会处理收到的SIGTERM信号进行优雅收尾退出。如果是/bin/sh格式的话,主进程是一个sh -c的进程,shell不用trap做信号捕捉、信号处理的话是无法转发信号的。最终只能强制Kill掉。
以EXEC风格示例
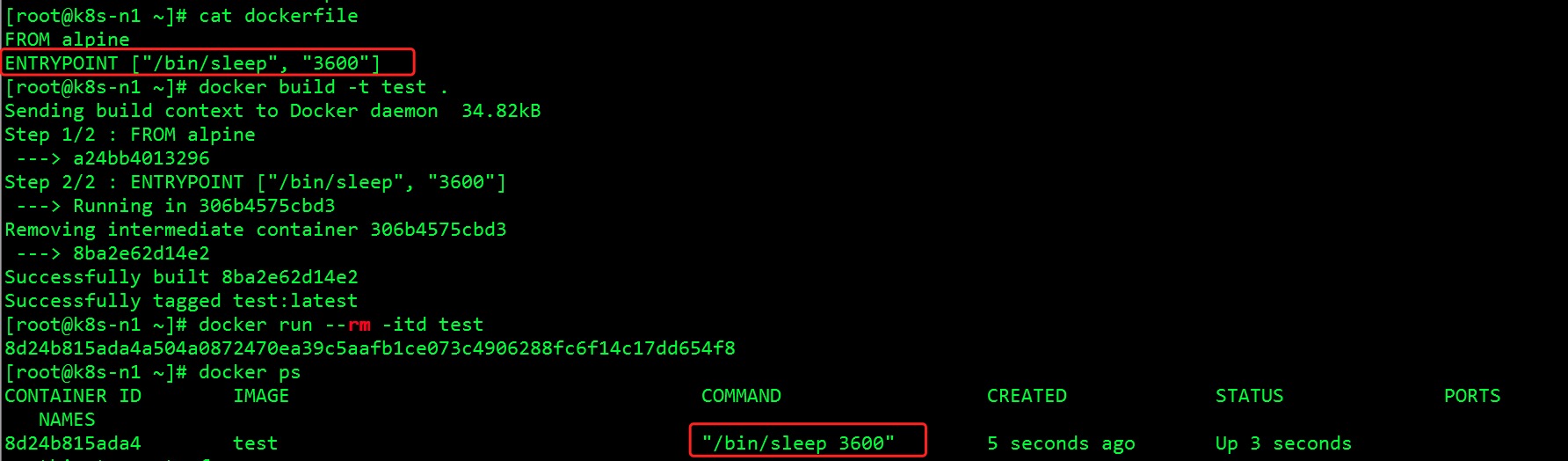
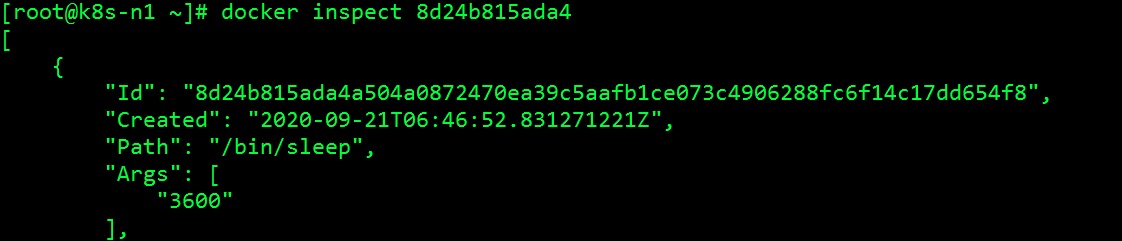

这样不会独立启动一个shell进程,应用的可执行程序(/bin/sleep)成为容器的PID 1进程,可以接收Unix信号。
ENTRYPOINT与CMD指令
- CMD: 指定容器启动时默认执行的命令。
- ENTRYPOINT: 指定容器启动时所运行的可执行程序与参数。
上面提到CMD是设置容器启动时的默认命令,既然是默认命令那么就是可以被替换的。当我们执行 docker run [OPTIONS] IMAGE [COMMAND] [ARG...] 镜像后面的command和arg会覆盖掉镜像的CMD。如果ENTRYPOINT和CMD指令同时存在一个dockerfile中,则ENTRYPOINT优先级高于CMD,CMD指令将被作为参数传递给ENTRYPOINT。最终运行的是 <ENTRYPOINT> <CMD>。
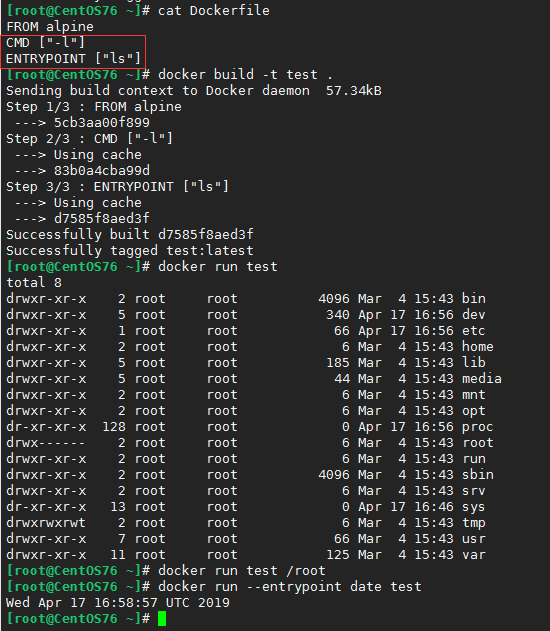
1、首先docker run的时候我们替换掉了CMD里面的'-l'指令。变成了 ls /root 但是alpine的root目录是没有文件,所以ls /root没有输出。
2、我们用选项去覆盖住entrypoint可以看到输出了date。注意一点是覆盖entrypoint的时候镜像的CMD会被忽略。
Docker容器优雅终止方案
作为一名系统重启工程师(SRE),你可能经常需要重启容器,毕竟 Kubernetes 的优势就是快速弹性伸缩和故障恢复,遇到问题先重启容器再说,几秒钟即可恢复,实在不行再重启系统,这就是系统重启工程师的杀手锏。然而现实并没有理论上那么美好,某些容器需要花费 10s 左右才能停止,这是为啥?有以下几种可能性:
- 容器中的进程没有收到 SIGTERM 信号。
- 容器中的进程收到了信号,但忽略了。
- 容器中应用的关闭时间确实就是这么长。
对于第 3 种可能性我们无能为力,本文主要解决 1 和 2。
如果要构建一个新的 Docker 镜像,肯定希望镜像越小越好,这样它的下载和启动速度都很快,一般我们都会选择一个瘦了身的操作系统(例如 Alpine,Busybox 等)作为基础镜像。
问题就在这里,这些基础镜像的 init 系统 也被抹掉了,这就是问题的根源!
init 系统有以下几个特点:
- 它是系统的第一个进程,负责产生其他所有用户进程。
- init 以守护进程方式存在,是所有其他进程的祖先。
- 它主要负责:
- 启动守护进程
- 回收孤儿进程
- 将操作系统信号转发给子进程
Docker 容器停止过程
对于容器来说,init 系统不是必须的,当你通过命令 docker stop mycontainer 来停止容器时,docker CLI 会将 TERM 信号发送给 mycontainer 的 PID 为 1 的进程。
- 如果 PID 1 是 init 进程 - 那么 PID 1 会将 TERM 信号转发给子进程,然后子进程开始关闭,最后容器终止。
- 如果没有 init 进程 - 那么容器中的应用进程(Dockerfile 中的 ENTRYPOINT 或 CMD 指定的应用)就是 PID 1,应用进程直接负责响应 TERM 信号。这时又分为三种情况:
- 应用不处理 SIGTERM - 如果应用没有监听 SIGTERM 信号,或者应用中没有实现处理 SIGTERM 信号的逻辑,应用就不会停止,容器也不会终止。
- 应用收不到 SIGTERM 信号 - 在写dockerfile时ENTRYPOINT 或 CMD使用
shell模式会导致应用无法收到SIGTERM信号,因为shell不会转发信号到子进程 - 应用收到 SIGTERM 信号并处理信号
第一种和第二种会导致容器停止时间很长 运行命令 docker stop mycontainer 之后,Docker 会等待 10s,如果 10s 后容器还没有终止,Docker 就会绕过容器应用直接向内核发送 SIGKILL,内核会强行杀死应用,从而终止容器。
容器进程收不到 SIGTERM 信号?
如果容器中的进程没有收到 SIGTERM 信号,很有可能是因为应用进程不是 PID 1,PID 1 是 shell,而应用进程只是 shell 的子进程。而 shell 不具备 init 系统的功能,也就不会将操作系统的信号转发到子进程上,这也是容器中的应用没有收到 SIGTERM 信号的常见原因。
问题的根源就来自 Dockerfile,例如:
1 | |
ENTRYPOINT 指令使用的是 shell 模式,这样 Docker 就会把应用放到 shell 中运行,因此 shell 是 PID 1。
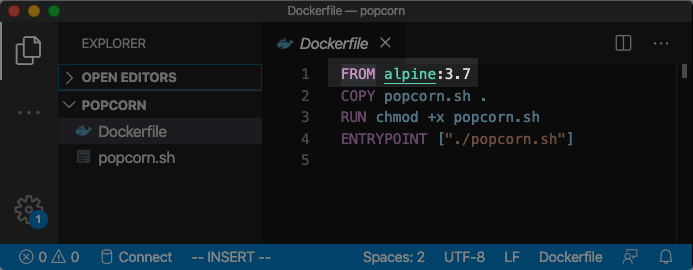
解决方案 1:使用 exec 模式的 ENTRYPOINT 指令
1 | |
这样 PID 1 就是 ./popcorn.sh,它将负责响应所有发送到容器的信号,至于 ./popcorn.sh 是否真的能捕捉到系统信号,那是另一回事。
举个例子,假设使用上面的 Dockerfile 来构建镜像,popcorn.sh 脚本每过一秒打印一次日期:
1 | |
构建镜像并创建容器:
1 | |
打开另外一个终端执行停止容器的命令,并计时:
1 | |
因为 popcorn.sh 并没有实现捕获和处理 SIGTERM 信号的逻辑,所以需要 10s 左右才能停止容器。要想解决这个问题,就要往脚本中添加信号处理代码,让它捕获到 SIGTERM 信号时就终止进程:
1 | |
解决方案 2:使用 init 系统
如果容器中的应用默认无法处理 SIGTERM 信号,又不能修改代码,这时候方案 1 行不通了,只能在容器中添加一个 init 系统。init 系统有很多种,这里推荐使用 tini,它是专用于容器的轻量级 init 系统,使用方法也很简单:
- 安装 tini
- 将 tini 设为容器的默认应用
- 将
popcorn.sh作为 tini 的参数
具体的 Dockerfile 如下:
1 | |
现在 tini 就是 PID 1,它会将收到的系统信号转发给子进程 popcorn.sh。
如果你想直接通过 docker 命令来运行容器,可以直接通过参数
--init来使用 tini,不需要在镜像中安装 tini。如果是 Kubernetes 就不行了,还得老老实实安装 tini。
使用 tini 后应用还需要处理 SIGTERM 吗?
最后一个问题:如果移除 popcorn.sh 中对 SIGTERM 信号的处理逻辑,容器会在我们执行停止命令后立即终止吗?
首先启动两个容器一个容器使用 init 一个容器不使用 init。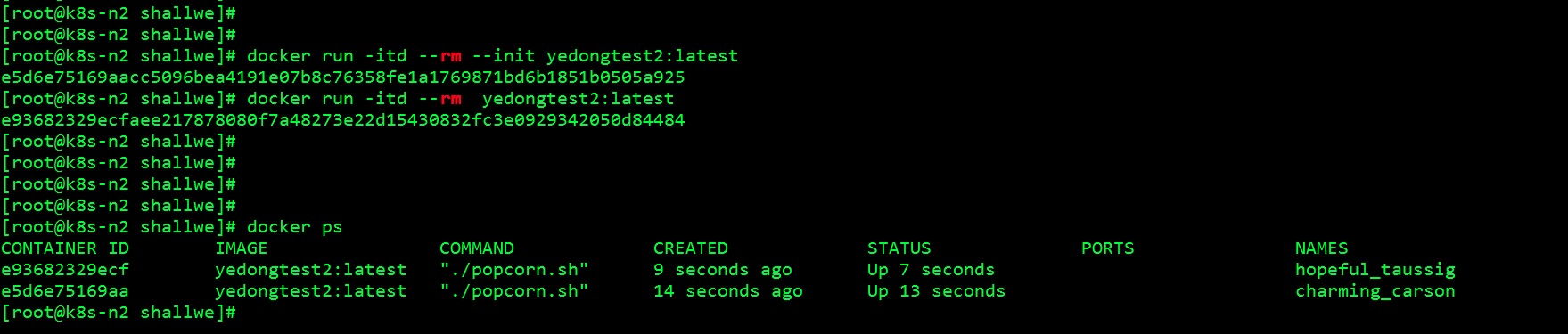
停止两个容器查看耗时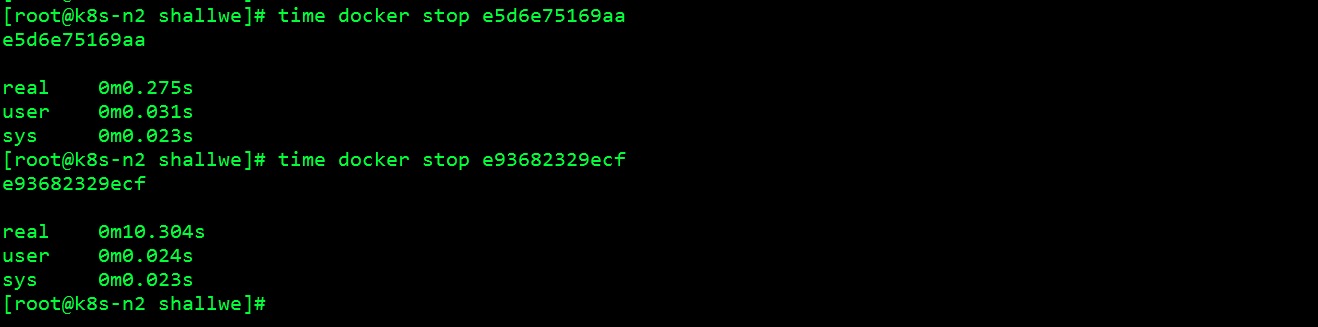
结果:可以优雅关闭容器